개요
오늘은 semantic segmentation에서 더욱 진보된 형태인 Instance/Panoptic segmentation, 그리고 또 다른 CV task인 landmark localization에 대해서 다루었다. 마지막으로 GAN에 대해서도 살펴보았다. 어제도 그렇고, 현재 다루고 있는 내용들은 사실 짧은 시간 내에 모두 깊게 살펴보기에는 어려운 부분이 많다. 그래서 큰 그림을 먼저 이해하고 세세한 내용은 추후 다시 살펴보는 것이 바람직할 것 같다.
이 글은 아래와 같은 내용으로 구성된다.
- Instance Segmentation
- Panoptic Segmentation
- Landmark Localization
- Detecting objects as Keypoints
- Conditional Generative Model
- Image translation GANs
- Various GAN applications
- Reference
Instance Segmentation
instance segmentation은 기존 semantic segmentation의 task에 distinguishing instances, 즉 인스턴스별 레이블이 다르게 매겨지는 것까지를 원한다. 어떻게 보면 비슷한 task를 수행하므로 여기서는 기존 semantic segmentation에 쓰였던 Faster R-CNN과 YOLO 등의 모델을 확장하여 활용하게 된다.
Mask R-CNN
먼저 Mask R-CNN을 살펴보자. Mask R-CNN은 Faster R-CNN과 거의 똑같다. 다만 거기에 mask branch라는 새로운 단이 추가된다.
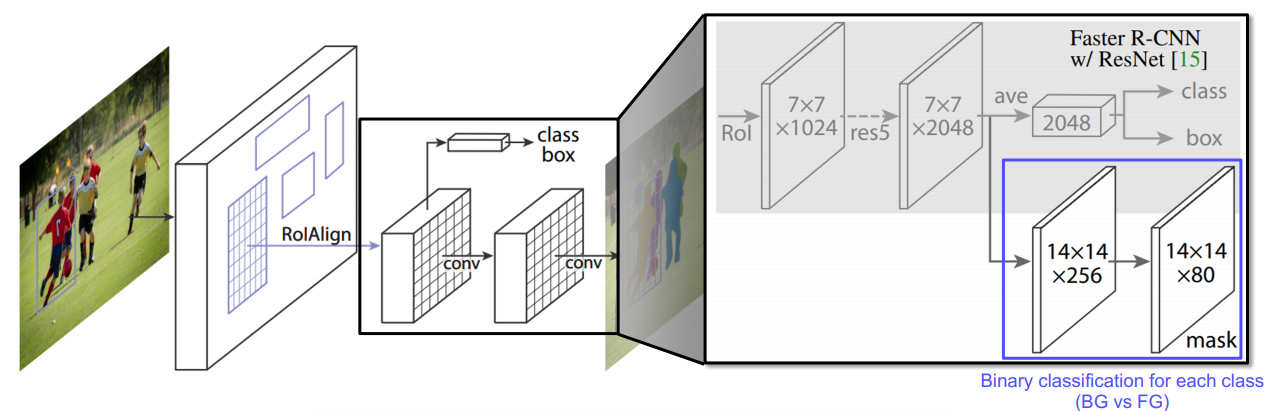
또 다른 차이점으로, RoI Pooling 대신 RoIAlign이라는 기법이 사용된다. 기존 RoI Pooling은 RoI가 소수점 좌표를 가지고 있을 경우 반올림하여 Pooling을 해준다는 특징이 있다. (딱 grid 단위로 쪼개서 본다)
즉, RoI Pooling은 정수 좌표만을 처리할 수 있다. 이러한 처리는 classification 처리에서는 문제가 없지만 segmentation task에서는 위치가 왜곡되기 때문에 문제가 발생한다.

Mask R-CNN에서는 RoIAlign이라는 기법을 활용한다. 현재 문제는 정수 좌표만 볼 수 있다는 점이다.
RoIAlign은 정수 좌표(즉, 점선으로 되어있는 grid 좌표)를 가지고 bilinear interpolation을 한다.
최종적으로 구하고자 하는 점에 해당하는 feature 값을 구할 수 있게 된다.
이 방법을 통해 보다 정교한 feature 값을 뽑아낼 수 있게 되어 큰 성능향상을 보였다고 한다.
한편, 맨 위에 첨부한 이미지를 보면 class/box regression head 외에 아래쪽에 새로운 mask branch가 도입되었다. 이 부분에서는 각 class별로 binary mask prediction을 수행한다. 먼저 upsampling을 한 후 클래스 수만큼의 mask(여기서는 80개)를 모조리 생성한 후 위쪽 head에서 해당 이미지의 classification을 완료하면 이를 참조하여 그 class에 해당하는 mask를 최종적으로 출력하게 된다.
그 외에도 RPN이전 feature map 추출 단게에서 FPN 구조를 활용하여 전후의 정보를 모두 고려해주었다는 특징이 있다. 이렇게 U-Net, FPN과 같은 구조는 이후에도 게속해서 쓰이는데 이 구조가 아무래도 전체 context를 고려할 수 있어 성능이 보장되는 면이 있는 것 같다.
YOLACT / YolactEdge
YOLACT는 이름에서 보이듯이 YOLO를 확장한 모델이다.
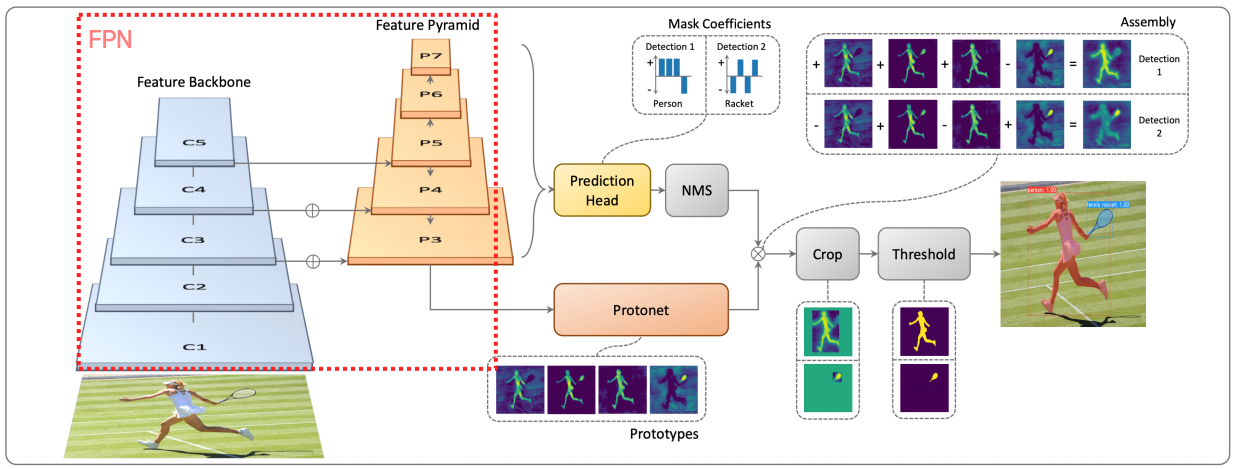
여기서도 FPN 구조를 활용하였고 이번엔 Protonet을 도입하여 mask의 prototype을 추출한다.
prototype이란, 추후에 마스크를 만들 수 있는 재료를 뜻한다. 선형대수학으로 보면 mask space를 span하는 basis가 여기에 해당한다고 보면 될 것 같다.
결국 protonet 단에서는 이 basis를 추출한다.
이제 basis를 추출했으면 앞에 붙는 계수(coefficient)도 있어야 mask를 만들 수 있다. Prediction head단에서는 각 detection에 대하여 protoype 합성을 위한 계수를 출력해낸다. 최종적으로 bounding box에 맞추어 이를 선형결합(weighted sum)한 후 Crop/Threshold를 거쳐 mask response map을 생성한다.
여기서의 핵심은 역시 Prototype 단이다. Mask R-CNN은 각 클래스별 mask를 모두 뽑아낸다. 이렇게 되면 메모리에 부담이 있을 수 있는데 YOLACT는 prototype을 미리 설정해 저장해야하는 mask의 수를 최소화한다는 특징이 있다.
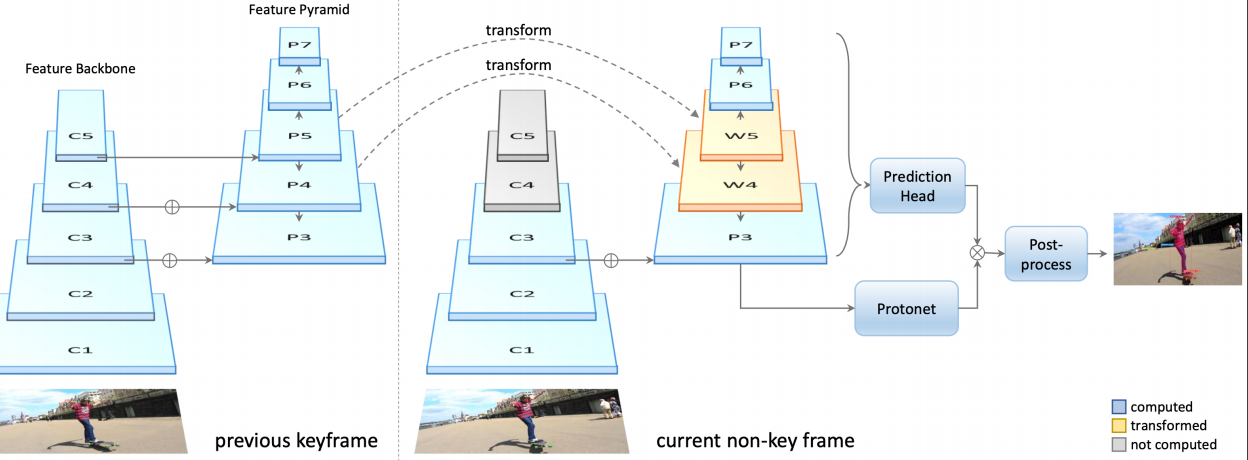
또 다른 모델로 YolactEdge가 있다. YOLACT는 빠르지만 경량화된 모델은 아니라서 작은 device에서 활용하기 어렵다.
YolactEdge는 위와 같이 YOLACT에서 바로 이전 time의 keyframe의 FPN에서 추출된 특징을 현재 time에서도 재활용하여 계산량을 최소화하였다.
하지만 아직도 video에서 완전한 real time task를 수행하기에는 한계점이 많아 비디오에서의 실시간 처리는 아직까지 연구중인 분야라고 한다.
Panoptic Segmentation
panoptic segmentation은 instance는 물론이고 배경의 segment까지 추출할 수 있는 모델이다. semantic segmentation은 배경을 인식할 수 있지만 같은 클래스의 instance를 구별해내지 못한다. instance segmentation에서는 배경을 추출할 수 없다. panoptic segmentation은 따라서 이 둘의 특성을 모두 활용한다.
UPSNet
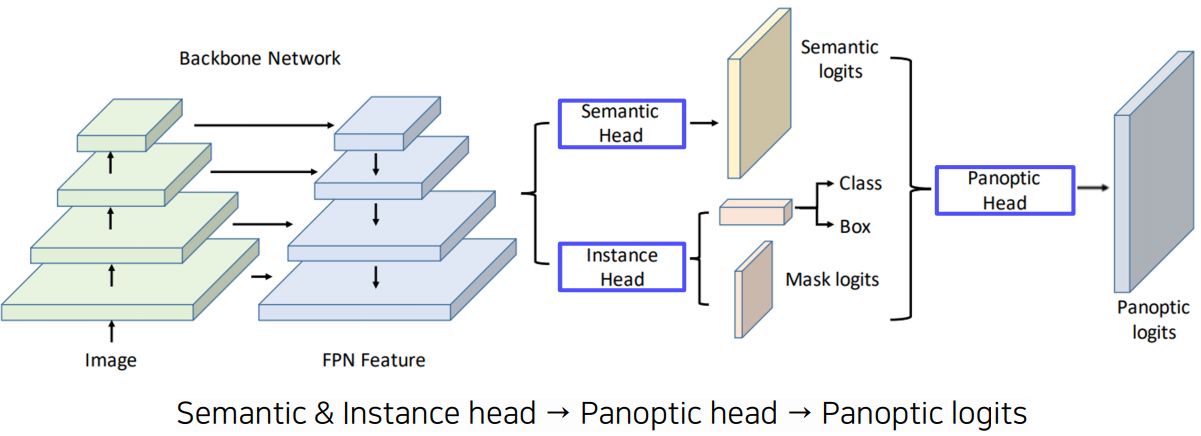
UPSNet은 panoptic segmentation을 위해 2019년에 제시된 모델이다. 시기만 봐도 이 분야의 개척이 시작된지 얼마 되지 않았음을 알 수 있다. ![]()
역시 FPN 구조를 앞단에서 활용하고 뒷단에서는 semantic head와 instance head를 각각 두어 윗단에서는 semantic segmenation을 수행하는 FCN처럼 conv 연산을 수행하여 segment prediction을 한다. 아랫단에서는 물체에 대한 detection을 통해 mask logit을 찾는다. 최종적으로 이 두 정보를 함께 활용하여 panoptic logits를 도출할 수 있다.
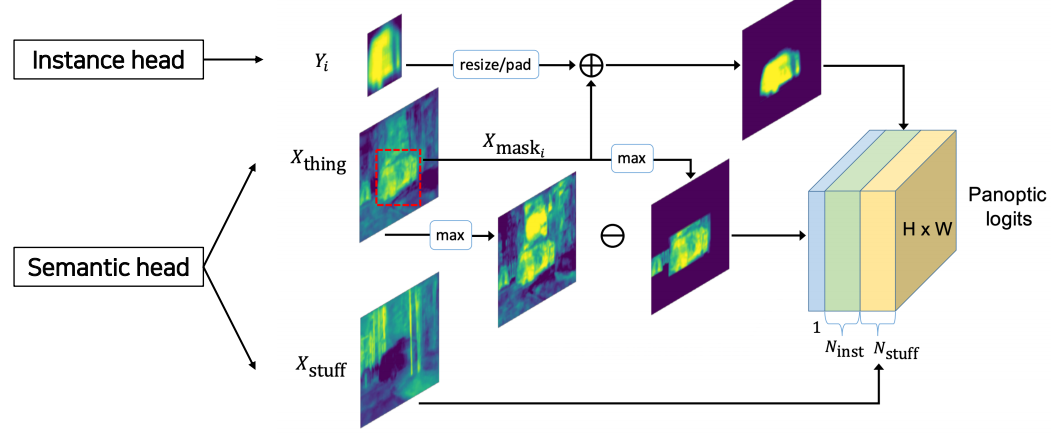
두 정보를 통합하여 이용하는 panoptic head쪽을 좀 더 자세히 살펴보자.
instance head에서 흘러온 feature는 원래 이미지의 원래 위치에 넣어주기 위해 resize/pad를 한다. semantic head에서 흘러온 정보는 먼저 semantic의 배경 부분을 나타내는 mask를 바로 output으로 흘려보내고($x_{\text{stuff}}$), 물체부분이 마스킹된 feature($x_{\text{thing}}$)의 경우 위쪽으로는 instance head의 원래 위치를 맞춰주기 위해 instance head의 출력과 함께 활용되고, 아래 쪽으로는 전체 feature에서 해당 물체에 대한 mask를 제거하기 위해 활용된다. 이걸 제거해서 생긴 부분은 unknown class로 활용된다.
최종적으로 이들 결과를 모두 concatenation하여 이를 panoptic logits으로 활용한다.
VPSNet
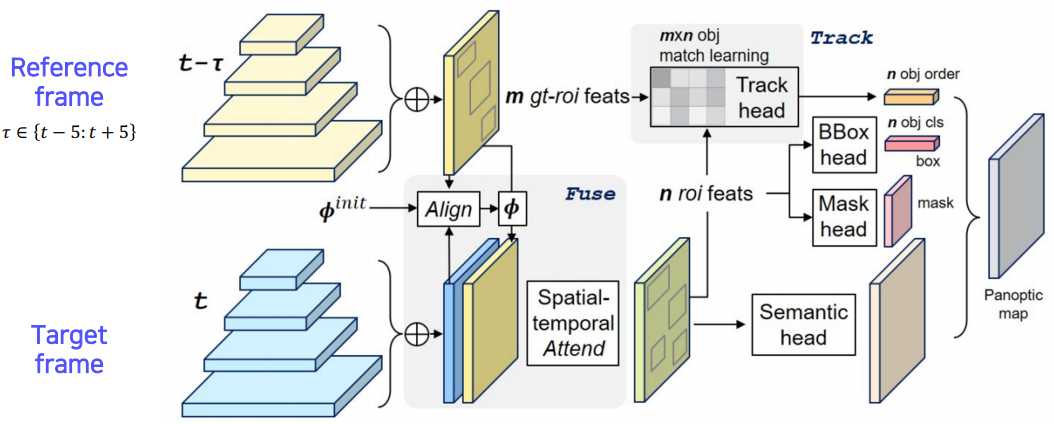
panoptic segmentation을 video에서 하기 위한 모델로 VPSNet이 있다. 여기서는 motion map을 활용한다.
motion map은 시간의 흐름에 따라 물체가 어디로 가는지, 즉 매 frame별 각 점들이 일대일로 대응되는 대응점들을 나타낸 map이다. (물론 새로 나타난 물체는 새로운 점이 필요하다)
프로세스는 다음과 같다. (1) 이전 시점($t - \tau$) RoI feature들을 motion map을 통해 현재 시점($t$)에서 tracking하고 (2) 현재 시점 $t$에서 또 따로 FPN을 통해 찾아낸 feature를 (1)에서 구한 것과 concatenation한 후 이를 통해 최종적으로 현재 시점의 RoI feature를 추출한다. (3) 이전 시점 RoI feature와 현재 시점 RoI feature를 Track head의 input으로 주어 최종적으로 두 시점의 RoI간 연관성을 추출해내고 마지막으로 그 뒷단에서는 UPSNet과 같은 작업을 수행한다.
VPSNet은 track head를 통해 같은 물체는 같은 id를 가지도록 시간에 따른 tracking을 수행한다.
Landmark Localization
landmark localization은 keypoint estimation이라고도 불리는데, 한마디로 주어진 이미지의 주요 특징 부분(landmark, keypoint)를 추정/추적하는 task를 말한다. 여기서 landmark라 함은 사람의 얼굴의 눈, 코, 입이라거나 사람 전신의 전체 뼈대(skeleton) 등을 생각해볼 수 있다. 물론 landmark를 무엇으로 정하느냐는 어떤 이미지에 대한 작업인지에 따라 다르며 이는 모델을 짜는 사람이 미리 정해야하는 hyperparameter라고 볼 수 있다.
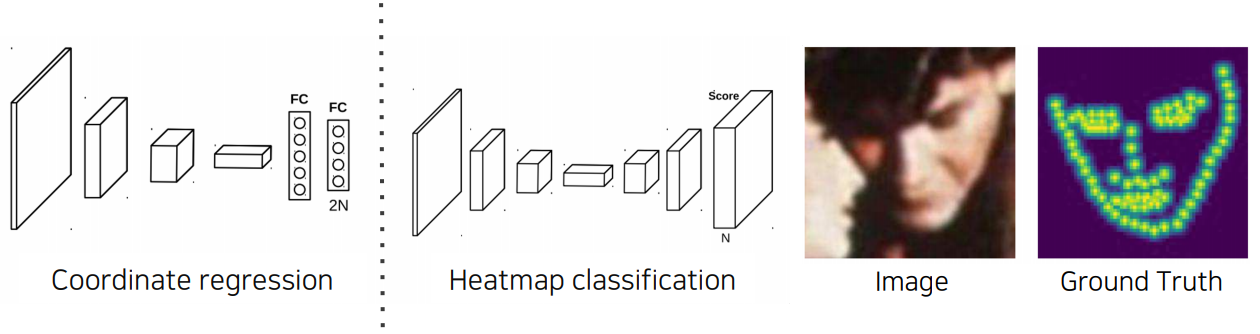
이를 위한 방법으로 coordinate regression을 먼저 생각해볼 수 있다. 모든 landmark 후보 각각에 대하여 각각의 x, y 좌표를 예측하는 방법이다.
하지만 이건 좀 부정확하고 generalization에 있어 문제가 있다.
여기서는 대신 heatmap classification을 다뤄보고자 한다. heatmap classification은 coordinate regression보다 성능이 더 우월하다.
heatmap classification의 최종 결과값은 각 채널이 사전 정의한 landmark 각각에 대한 위치별 확률값을 나타내게된다. 이전에 본 semantic/instance segmentation에서 수행했던 작업과 유사하다. 결국 여기서의 차이점은 keypoint 각각을 하나의 class로 생각하고 그걸 기반으로 각 keypoint별 heatmap을 찍어주는 것 뿐이다. 다만 이 방법은 모든 픽셀에 대한 확률을 그려야 하므로 computational cost가 높다는 단점이 있다.
heatmap classification을 위해서는 결국 landmark가 어떤 좌표 (x, y)에 있는지를 우선적으로 찾아야한다. 그런데 딱 그 위치에서 ground truth(확률값 label)가 1이고 그 주변은 모두 0이면 학습이 제대로 안 될 것이다. 그래서 먼저 각 landmark가 존재하는 실제 위치 (x, y)를 가지고 그 주변에 heatmap label을 만들어야한다.
이를 위해 여기서는 Gaussian heatmap을 다뤄보도록 한다.
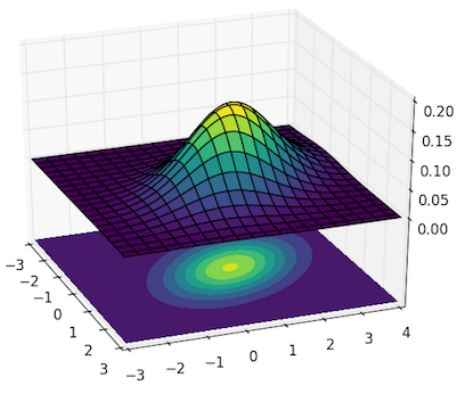
방법은 간단하다. 해당 물체가 있는 실제 위치 $(x_c, y_c)$를 기준으로 주변 좌표들에 Gaussian 분포를 적용하면 된다. 그러면 위와 같이 confidence 값에 대한 heatmap label을 만들 수 있다.
식은 아래와 같다.
$\sigma$는 hyperparameter로 heatmap label을 얼마나 퍼뜨려줄지 직접 정해야한다.
실제 구현에서 x좌표와 y좌표는 그 dimension이 다르지만 numpy에서 broadcasting을 적용하므로 최종적으로 2차원의 heatmap을 얻을 수 있다.
그렇다면 Gaussian heatmap에서 landmark location으로의 변환은 어떻게 할 수 있을까? 지금 당장 내 생각에는 Gaussian heatmap에서 확률값이 가장 높은 부분을 찾으면
그곳이 landmark의 실제 위치일 것 같은데 일단 이 부분은 숙제로 남겨두도록 한다.
Hourglass network
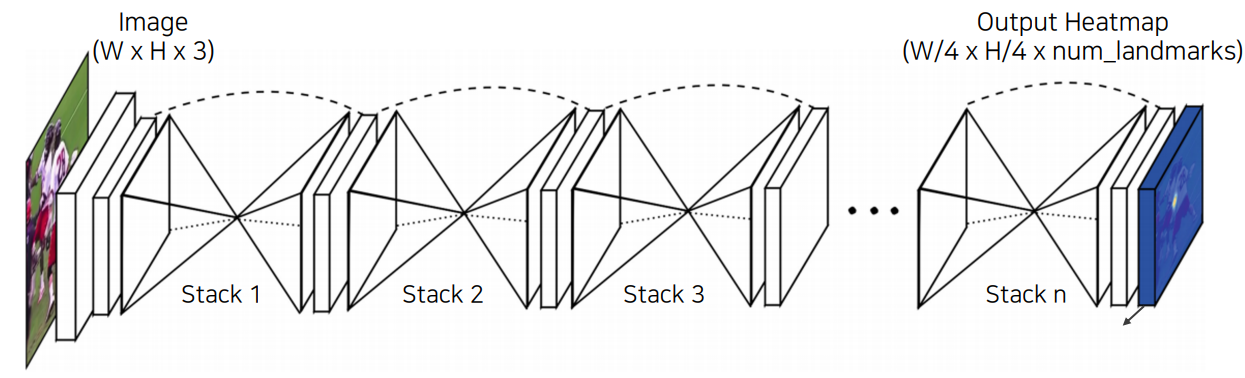
Hourglass network에서는 stack된 구조가 모래시계(hourglass)처럼 생겼다고 해서 붙여진 이름이다.
모래시계 구조는 역시 UNet 구조와 매우 유사하게 생겼다. 다만 여기서는 그런 구조를 여러번 stack하였다.
이렇게 하여 row level의 정보와 high level의 정보를 모두 인식하고, 이를 반복함으로써 성능을 더욱 개선한다.
또한 맨 앞단에서는 영상 전체에서 feature map을 미리 추출하여 각 픽셀이 receptive field를 더욱 크게 가져갈 수 있도록 해주었다.
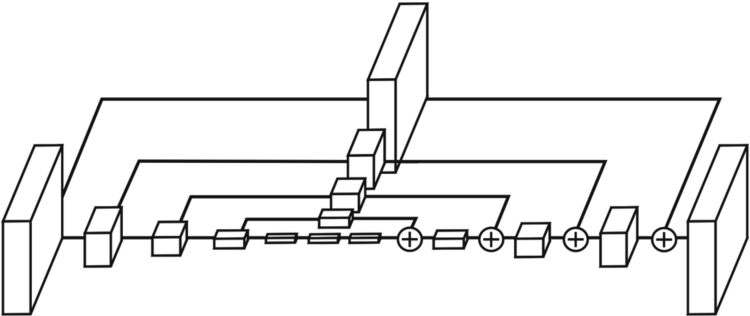
hourglass 모양 부분(stack)은 위와 같이 UNet과 매우 유사하다.
차이점을 위주로 보자면 (1) skip connection을 할 때 conv 연산을 해주고 전달한다. UNet에서는 이런 과정 없이 바로 전달하였다.
또한 (2) concatenation 대신 sum을 활용하였다. 이렇게 하면 dimension이 늘어나지 않는 특징이 있다.
구조를 보면 UNet보다는 사실상 FPN에 가까운 구조이다. 아무튼 이런 피라미드 구조가 landmark localization task에서도 역시 잘 동작한다.
DensePose

DensePose는 기존 2D 좌표만을 예측하였던 모델에서 벗어나 3D 구조까지 예측한다.
위와 같이 3D pose estimation에 유용하다.
여기서는 UV map을 활용한다. UV map이란 쉽게 말해 3D 구조를 2D에 표현한 map을 의미한다.
이 map상에서는 물체의 위치가 시간에 따라 변화해도 그 좌표가 불변한다는 성질이 있다.
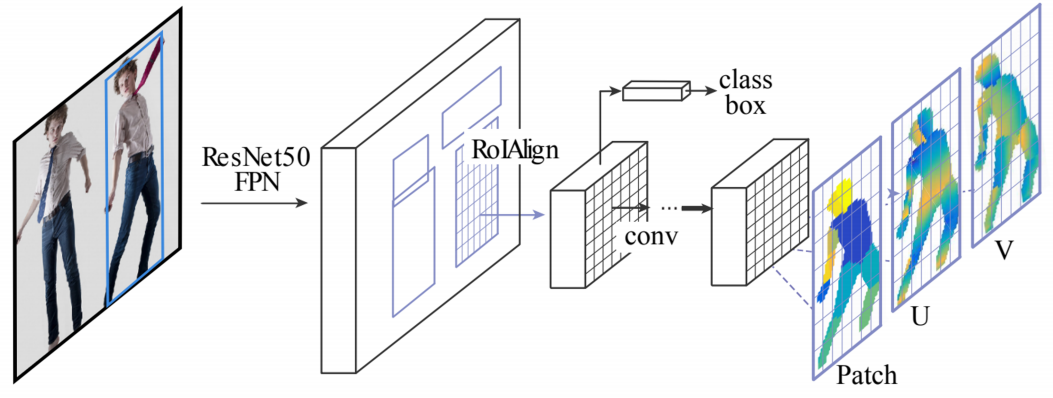
DensePose는 Mask R-CNN에서처럼 Faster R-CNN에 3D surface regression branch라는 새로운 브랜치를 얹는다.
위와 같이 각 body part에 대한 segmentation map을 추출해낼 수 있으며, 2D 구조의 CNN으로 3D 위치까지 예측할 수 있다는 데에 의의가 있다.
RetinaFace / More extension
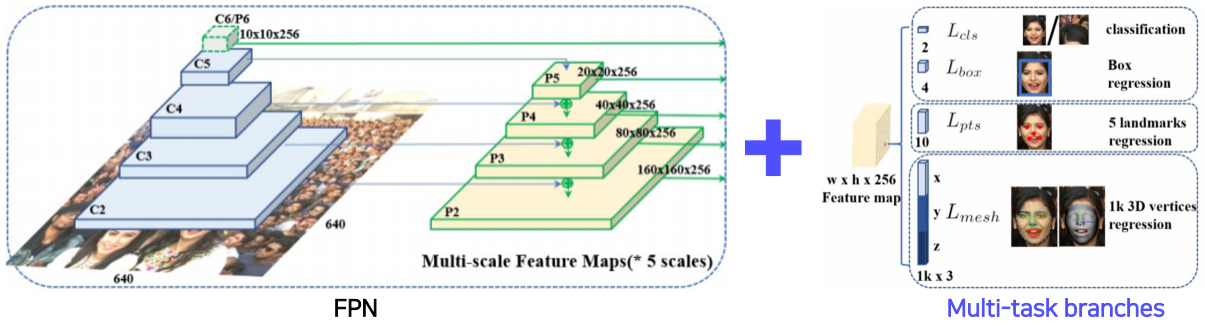
이후 나온 RetinaFace라는 모델에서도 FPN backbone에 task 수행을 위한 head를 얹는다.
특이한 점은, multi-task 수행을 위한 여러 branch를 모두 얹는다는 것이다.
위 그림을 보면 현재 사람의 얼굴에 대한 semantic segmentation, landmark regression, 3D vertices regression 등 여러 문제를 해결할 수 있는 헤드를 한꺼번에 얹었다. 물론 각 헤드가 수행하는 역할은 다르지만, 근본적으로 모든 것이 ‘사람의 얼굴’이라는 같은 대상에 대한 학습을 하므로 공통된 정보에 대한 역전파가 가능하다는 점이 이 모델의 핵심 아이디어다.
이렇게 하면 동시에 모든 task를 수행할 수 있는 동시에, backbone network가 더욱 강하게 학습된다. 사실상 데이터를 더 많이 본 효과를 낼 수 있다. 따라서 이러한 모델은 적은 데이터로도 보다 robust한 model을 만들 수 있게 된다.
여기서 깨달을 수 있는 점은, backbone은 계속 재활용/공용하더라도 target task를 위한 head만 새로 설계하면 다양한 응용이 가능하다는 것이다. 이러한 기조가 최근 CV 분야의 큰 디자인 패턴 흐름 중 하나이다.
Detecting objects as Keypoints
object detection을 할 때 bounding box가 아니라 keypoint 형태로도 detection을 할 수 있다. 결국 하고자하는 것은 같긴 한데, RoI를 먼저 찾거나 할 필요 없이 그냥 keypoint를 찾아서 그 keypoint를 기준으로 무언가 작업을 하면 object detection이 가능하다. 여기서는 이러한 작업을 수행했던 CornetNet과 CenterNet에 대해 아주 간단히 알아보고 넘어가도록 하자.
CornerNet
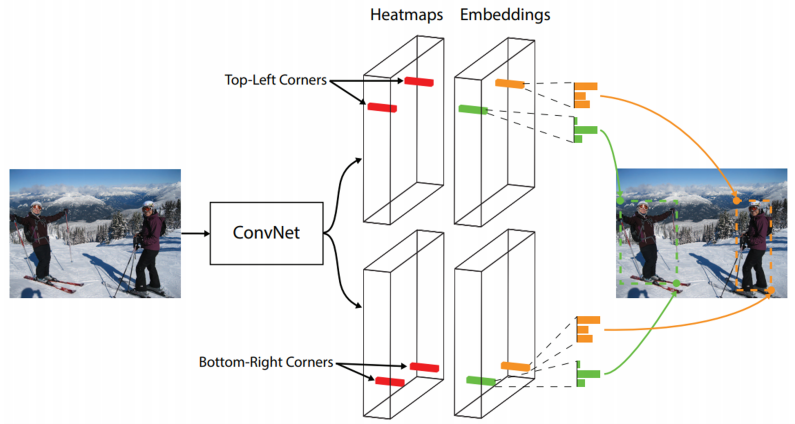
CornetNet은 좌측상단점과 우측하단점을 탐색하는 모델이다.
이를 위해 이미지를 backbone에 통과시키고 거기서 뽑아낸 피쳐맵을 총 4개의 head에 통과시킨다.
헤드 하나하나의 역할을 살펴보자면, (1) top-left corner 위치를 찾는 헤드, (2) 그것에 대한 embedding을 뽑아내는 헤드, (3) bottom-right corner 위치를 찾는 헤드, (4) 그것에 대한 embedding을 뽑아내는 헤드로 구성된다.
여기서 embedding head는 corner 점의 embedding을 뽑아내는데, embedding은 위 그림과 같이 각 점이 표현하는 정보를 나타내며, 같은 물체에 대한 점들은 같은 embedding을 나타내도록 학습된다. 따라서 각 점의 embedding의 결과를 참조하여 우리는 물체의 위치를 점 2개로 detection 할 수 있다. (점 2개로도 unique한 bounding box를 결정할 수 있다) 이 모델은 정확도보다는 속도에 무게를 주었다. 따라서 정확도는 좀 떨어지는 면이 있다.
CenterNet
CenterNet에서는 CornetNet을 개선하여 좌상, 우하에 더불어 중점까지도 탐색한다. center point를 추가로 도입함으로써 총 6개의 head가 필요하겠지만 이로 인해 정확도는 향상되었다.
더 진보된 CenterNet은 아예 중심점만을 찾고, 거기에 추가적으로 높이(height), 너비(width) 값을 찾는다.
이렇게 함으로써 얻는 장점은 무엇일까? 정확한 것은 논문을 읽어봐야 알겠지만, 직관적으로 먼저 생각을 해보자.
앞서 본 첫번째 CenterNet은 정확도가 향상되는 대신 head가 6개가 필요하였다. CornetNet에서는 정확도는 떨어지지만 head를 4개만 두어 속도를 취했다. 지금 보고있는 진보된 CenterNet은 CornerNet처럼 head를 4개만 두어 속도를 취하는 한편 동시에 이전 CenterNet과 같은 작업을 수행하므로 둘 모두의 장점을 취했다고 이해할 수 있다.
이렇게 만들어진 CenterNet은, 논문에서 Faster R-CNN/Retina Net/YOLOv3의 object detection보다도 성능 및 속도면에서 우월했음을 제시하고 있다.
Conditional Generative Model
![]() 지금부터 다룰 내용은 에서 이미 관련 내용을 다루고 있으니 이 내용을 참고하도록 하자. 여기서는 부족한 부분을 위주로 다룰 예정이다.
지금부터 다룰 내용은 에서 이미 관련 내용을 다루고 있으니 이 내용을 참고하도록 하자. 여기서는 부족한 부분을 위주로 다룰 예정이다.
지금부터 볼 모델은 구체적으로는 GAN이 아닌 Conditional GAN(CGAN)이다. GAN과 거의 다를 바가 없긴 한데, 여기서는 latent vector를 통해 random image를 생성하는게 아니라 원하는 것을 생성할 수 있다는 차이가 있다.
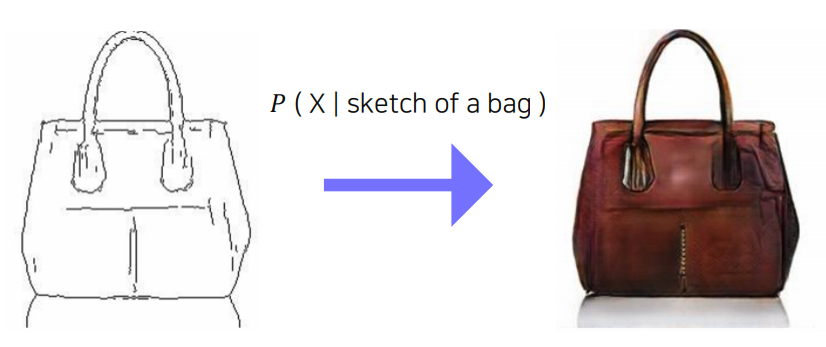
설명에 앞서, 우리가 하고자 하는 바를 먼저 생각해보자. 만약 우리가 위와 같이 가방의 sketch $S$로 실제 물체의 이미지 $X$를 만들고자 한다면, 다른 말로 우리의 목표는 확률분포 $P(X \vert S)$를 모델링하는 것이 된다.
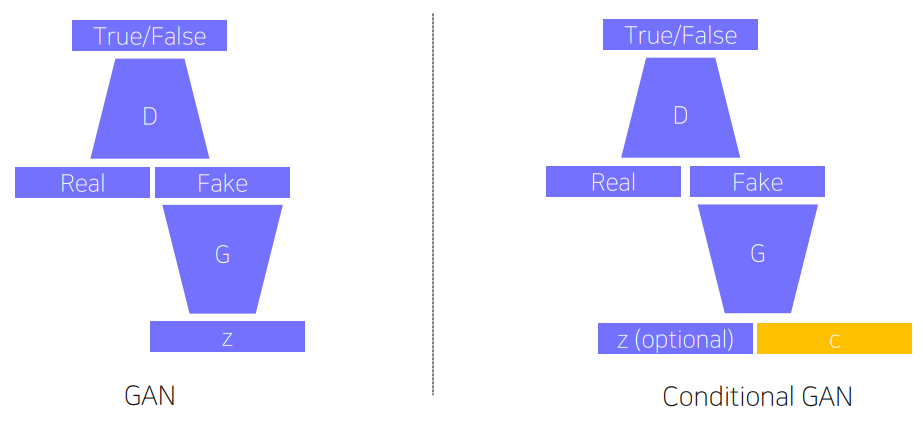
CGAN은 이러한 task를 위해 위와 같이 일반 GAN의 input에 conditional 정보를 넣어준다. 이 때, latent vector $\mathrm{z}$는 이제 필수가 아니다.
여기까지 보면 물체의 형상은 C에 의존적으로 생성되고 $\mathrm{z}$는 noise(물체의 style 요소 등)를 모델링하는 데에 영향을 줄 것임을 예상해볼 수 있다.
loss도 아래와 같이 $y$를 조건부로 넣어주는 부분만 바뀐다.
(Vanilla GAN)
(Conditional GAN)
CGAN은 여러 image translation(Image-to-Image translation) task에 활용될 수 있다. 예를 들어 주어진 사진의 색채 등 스타일을 변경한다든지(style transfer), 이미지의 해상도를 높인다든지(super resolution), 흑백 이미지를 컬러 이미지로 만든다든지(colorization) 등의 task가 있다.
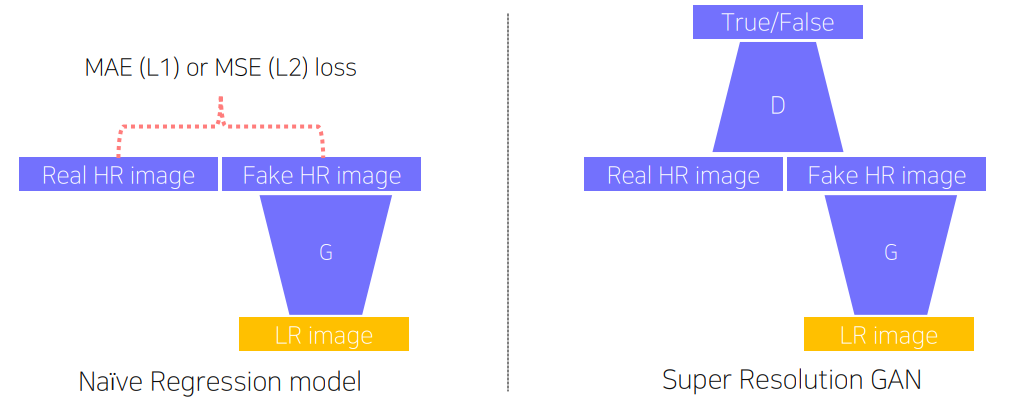
그런데 이러한 task에 CNN 등의 일반적인 regression model을 사용할 수도 있지 않을까 생각해볼 수 있다. 위 그림의 좌측처럼 말이다.
위 케이스는 super resolution(SR) task를 예시로 든건데 두 방법의 성능 차이는 어디서 나오게 되는걸까?
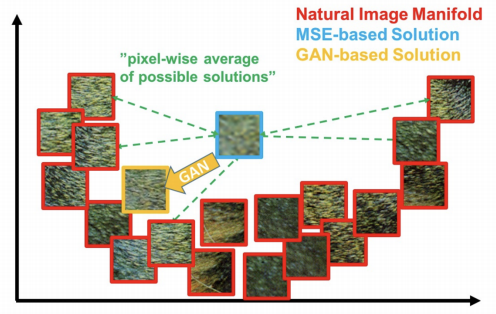
MSE loss를 base로 한 CNN 등의 모델을 generative model로 활용한다면 위와 같이 loss를 최소화하기 위해 어정쩡한 이미지를 생성하게 된다.
이것은 true image의 분포가 위와 같이 원 모양으로 퍼져있을 때 극단적으로 두드러질 수 있다. loss를 최소화하기 위해 모든 true image에 대한 loss의 합을 최소화하기 위해
오히려 true와 거리가 먼 이미지를 생성하게 되는 것이다.
반면 GAN loss(adversarial loss)를 활용하면 생성된 이미지가 원래 이미지와 가까운지가 아니라, 가짜 이미지인지 진짜 이미지인지만 판별하므로 이러한 현상이 발생하지 않는다. 앞서 본 naive model도 상황에 따라 어쩌면 원하는 형태와 비슷한 이미지를 생성하는데에 문제가 없을 수도 있겠지만 그렇다고 해도 여전히 loss를 최소화하기 위한 시도로부터 blurry image가 생성되는, 즉 선명한 이미지를 생성해낼 수 없다는 한계가 존재한다.
Image translation GANs
image translation이란 input으로 들어오는 이미지의 도메인(i.e., style)을 변경하는 task이다. 좀더 일반적으로 들어오는 이미지의 해상도는 그대로 유지하되, 일부 스타일만을 변경하는 것을 말한다.
그 중 하나로 Pix2Pix 방법론이 존재한다. 여기서는 GAN의 loss를 그대로 이용하게 되는데, 차이점이라면 추가적으로 L1 loss를 함께 활용한다.
Pix2Pix
GAN은 원래 이미지를 생성하는 모델인데, 여기서 원하는 것은 이미지를 밑바닥부터 생성하는 generative가 아니라 transfer이므로 단순히 GAN loss만 활용하는 것이 아니라고 이해할 수 있다. 따라서 이러한 사실을 적용한 Pix2Pix의 loss function은 아래와 같다.
이를 풀어쓰면 아래와 같다.
$z$는 random noise이고 $x$는 input image, $y$는 target image이다. 여기서도 conditional loss가 활용되었는데 논문에서는 일반 GAN보다 CGAN에서의 성능이 더 좋았기 때문에 이를 활용하였다고 명시되어있다.
CGAN loss는 realistic한 image의 출력을 유도하기 위해 활용되고, L1 norm은 생성하고자 하는 이미지에 대한 가이드로 활용된다. 만약 GAN loss만 활용한다면, 진짜 이미지만 생성하려고 하고 우리가 의도하는 이미지를 생성하지는 못할 것이다. $x$와 $y$의 실질적인 비교가 없기 때문이다. CGAN의 첫번째 항은 $x$와 $y$의 비교가 아니고 그저 진짜 이미지라는 틀 내에서 확률 분포가 비슷한지만 판별해낸다.
반대로 L1 norm만 활용한다면 우리가 원하는 이미지의 형태로 생성을 하겠지만 fake image의 티가 팍팍 나게 될 것이다.
여기서는 둘 모두의 장점을 취한 loss를 활용하여 최종적으로 아래와 같이 상당히 잘 translation된 이미지를 생성해낼 수 있었다.

CycleGAN
Pix2Pix는 pairwise data가 필요하다는 한계가 존재한다. Pix2Pix는 ground truth가 직접적으로 관여하기 때문에 supervised learning이다. supervised가 아닌 상태로 어떻게 학습을 하느냐는 의문이 들 수도 있지만, CycleGAN에서는 이를 해결한다.
여기서 필요한 데이터셋은 그냥 서로 다른 domain을 가지는 두 image set $\mathrm{X}$와 $\mathrm{Y}$ 뿐이다. 둘 간의 pairing 과정은 필요하지 않다.
CycleGAN이 왜 Cycle 구조를 가져야하는지, cycle구조가 정확히 어떻게 생겼는지는 하단에서 다루고 있으니 이를 참조하도록 하자.
여기서는 이전 포스트에서 다루지 않은 loss function에 대해 생각해본다. 함수 $G$와 $F$가 $G : X \rightarrow Y$, $F : Y \rightarrow X$일 때 loss function은 아래와 같다.
이를 좀 더 풀어쓰면 아래와 같다.
여기서 $\mathcal{L}_{\text{GAN}}$은 각 방향에 해당하는 Vanilla GAN의 loss를 나타낸다. 아래는 예시로 $X$에서 $Y$방향($G : X \rightarrow Y$)으로의 loss 식이다.
X에서 Y로, Y에서 X로, 양방향으로의 translation이 잘 되어야하므로 loss는 위와 같이 구성된다. 그런데 앞 포스트에서도 언급했듯이 translate된 이미지가 다시 원래대로 돌아올 수 있는 loss까지 학습해야한다. 따라서 최종 loss는 우리가 일반적으로 생각하는 GAN loss에 더불어 뒤에 Cycle-consistency loss 항까지 추가된다. 그림으로 보면 아래와 같다.
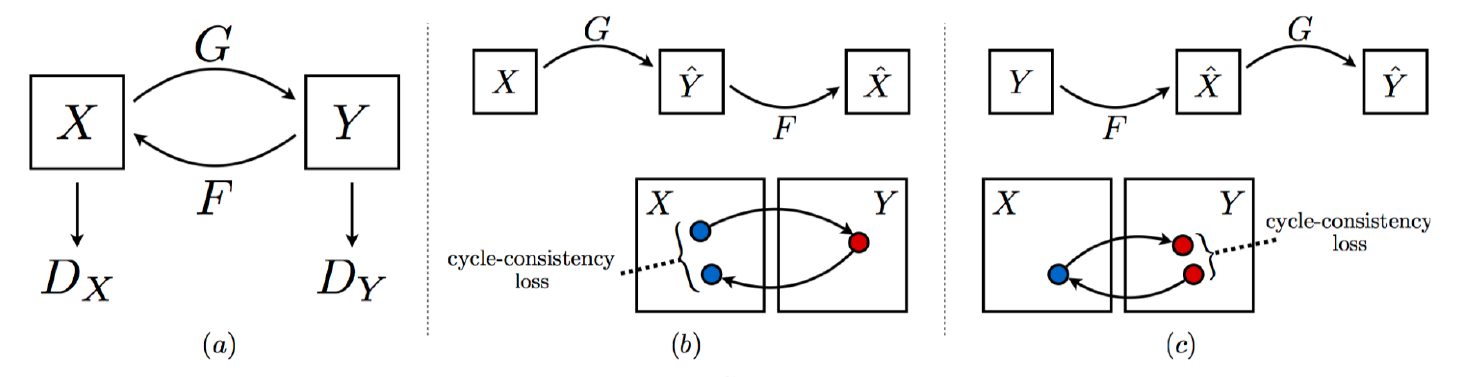
따라서 $\mathcal{L} _{\text{cycle}} (G, F)$은 아래와 같이 두 개의 generator를 거치고 나온 output이 원래 input과 같은지에 대한 정보를 반영해준다.
여담으로 이번 주차에서 워낙 모델을 많이 다루다보니 다양한 형태의 loss들을 보고있는데, loss function이 참 복잡하면서도 한편으로는 모델이 무엇을 배우려고 하는지를 한 눈에 볼 수 있다보니 뭔가 재밌는 것 같기도하다. 결국 모델의 설계 의도와 핵심은 모두 loss function에 담겨져있다.
Perceptual Loss
GAN loss는 계속해서 $\text{argmax}$와 $\text{argmin}$을 왔다갔다 하는 등 학습 자체가 좀 복잡하고 설계(코딩)하는 데에 어려운 점들이 있다. 물론 pre-train된 모델이 필요하지 않아 보다 다양한 어플리케이션에 적용할 수 있다는 장점이 있긴 하다.
Perceptual loss는 pre-trained model이 필요하지만 GAN loss와 비슷한 역할을 수행하면서도 구현이 간단하다는 장점이 있는 loss 함수이다.
perceptual loss의 아이디어는 이전에 살펴본 CNN visualization과도 연관이 있는데, 어떤 CNN 모델이 있으면 여러 level에서 나오는 activation map의 각 channel들이 담당하는 perception의 종류가 다르다는 것에서 출발한다. 우리는 이전에 모델의 각 채널이 어떤 것을 담당하는지 살펴보고 이를 응용해보는 task도 있다는 것을 배웠다.
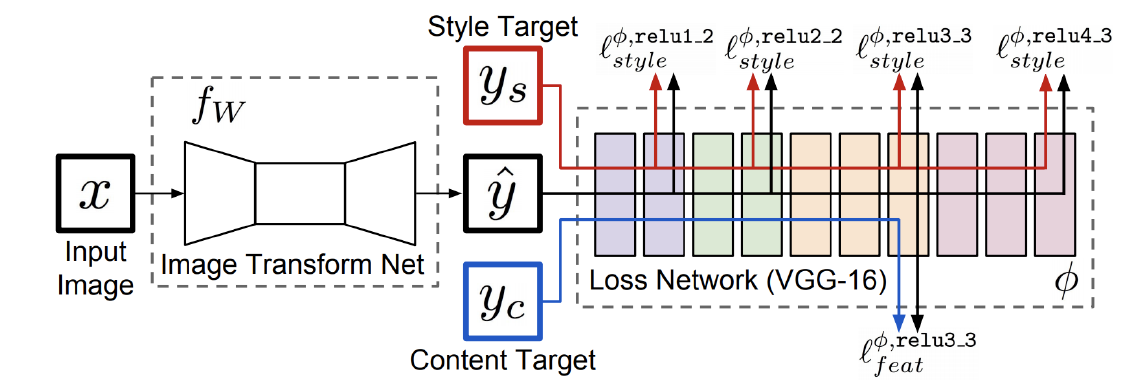
여기서는 먼저 image transform을 수행하는 앞단 모델에 input $x$를 넣어서 얻은 transform된 결과 $\hat{y}$를 pre-train된 모델에 넣어 각 level에서의 feature channel들을 추출한다.
그리고 style target과 content target도 같은 pre-trained model에 통과시켜 각 level에서 feature channel들을 얻는다.
우리의 목표는 $\hat{y}$의 feature map들이 style/content와 비슷해지도록 학습시키는 것이다.
이 때 당연히 미리 학습된 뒷단의 모델은 학습시키지 않고 transform performance를 향상시키기 위해 transform net만을 학습시킨다. 여기까지 보면 방식이 그리 어렵지 않다. 이제 $\hat{y}$를 style target과 content target에 구체적으로 어떻게 근사시킬것인지를 살펴보자.
그 전에, content target과 style target은 또 어떻게 얻을 것인지 의문이 생길 수 있는데, 그것들도 따로 어떻게 추출하는 방법이 논문에 제시되어있다. 이 부분을 자세히 읽어보진 않았고 지금 당장은 깊게 팔 생각이 없기 때문에(…) 이 부분은 일단 넘기고, 그걸 어떻게 근사시킬지만 알아보도록 하자.
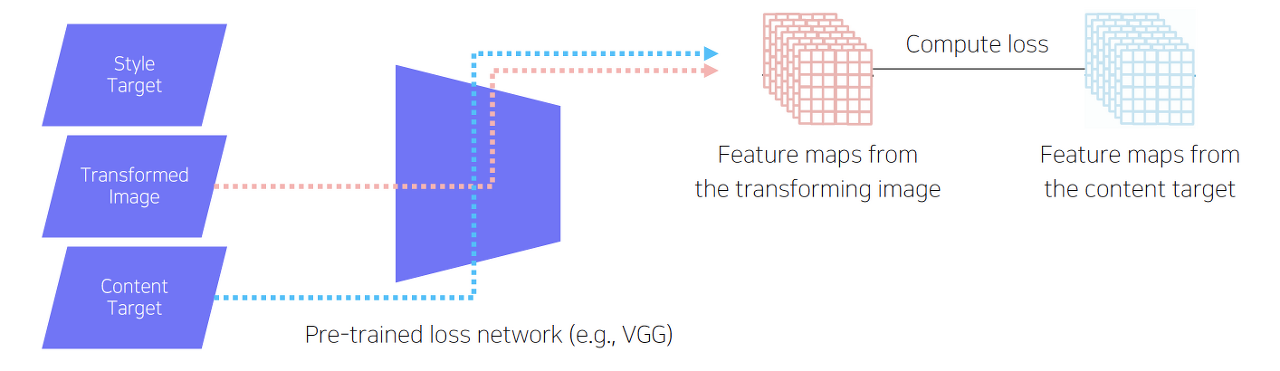
먼저 content target은 그냥 L2 loss를 계산한다. 매우 간단하지만 또 강력한 방법이라 이를 채택한 것 같다.
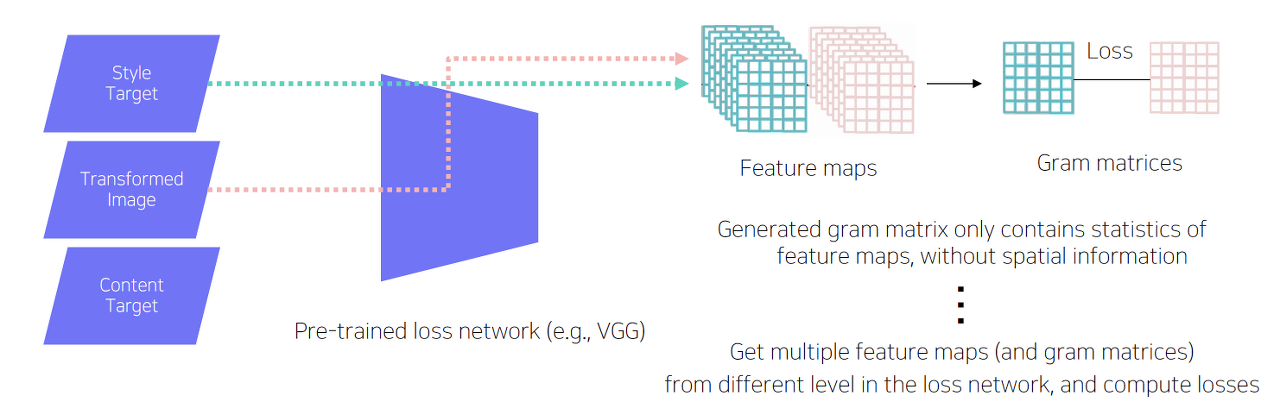
style target에서는 바로 L2 loss를 적용할 수 없다. 당장 생각해봐도 우리는 스타일을 바꿀건데 단적인 예로 이미지에 노란색 픽셀 부분이 있다면 바뀐 이미지에서도 그 부분이 꼭 노란색일 필요가 없다. (오히려 그러면 안되는 경우도 있다.)
따라서 여기서는 추출된 feature 상의 채널 간 연관성을 따진다. 이를 위해 pre-trained model에서 추출한 feature map을 그대로 활용하지 않고, 먼저 이들의 gram matrix를 각각 구하여 그 둘간의 L2 loss를 구한다.
gram matrix란 C x H x W 의 tensor를 C x (H x W)의 2차원 행렬로 펼치고 이 펼친 행렬과 펼친 행렬을 transpose한 행렬을 곱해서 구할 수 있다. 결국 각 채널별 정보를 내적한다는 것인데, 딱봐도 각 채널간 유사도를 결과값 행렬이 표현해낼 수 있다는 것을 예상해볼 수 있다. (C x C 크기의 행렬이 나올 것이다)
공분산 행렬(covariance matrix)을 구하는 과정과 코사인 유사도를 구하는 과정을 함께 생각해보면 쉽게 이해할 수 있다.
아무튼 그렇게 gram matrix를 transformed image, style target에서 각각 구해 이 둘 간의 L2 loss를 찾는다. 우리는 최종적으로 채널간 연관성이 유사해지는 학습을 할 수 있게 된다.
Various GAN applications
번외로 GAN이 적용될 수 있는 분야에 대해 잠깐 살펴보도록 한다.
흔히들 아는 Deepfake는 실존하지 않는 사람의 얼굴을 생성하거나 영상에 등장하는 사람의 얼굴이나 목소리를 의도한 다른 형태로 변형하는 기술을 말한다. 물론 이부분은 윤리적 문제가 많다. 범죄 예방을 위해 다각도의 시도가 계속되고 있으며 반대로 Deepfake를 탐색하는 discriminator를 개발하는 기술도 연구되고 있다.
하지만 Deepfake가 꼭 도덕적 악영향만 있는 것은 아니다. 어떤 영상에서 deepfake를 이용해 해당 영상에 등장하는 사람의 개인정보(얼굴/목소리 등)를 보호할 수도 있다. 컴퓨터의 인식력은 매우 민감하기 때문에 원래의 모습에서 조금만 변경하더라도 같은 사람으로 인식하지 못하는 경우가 많다고 한다.
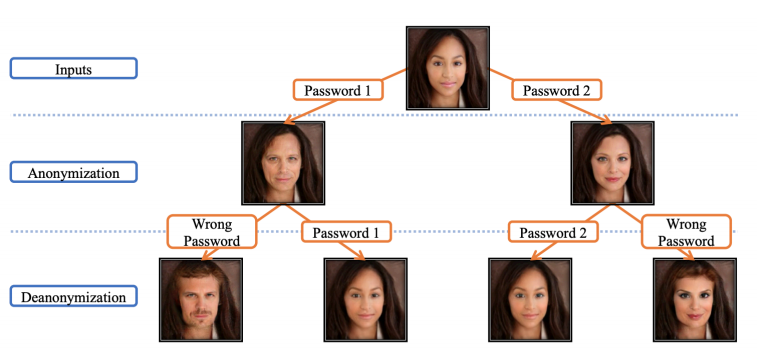
Face de-identification이라는 기술은 일종의 이미지 crypto 기법인데, passcode를 이용해 다른 얼굴을 생성하고 다시 이 passcode를 이용해 원래 얼굴을 복원(decrypt)해낸다.
어떤 원리인지는 몰라도 개인적으로 이 기술은 꽤나 재미있게 느껴졌다.

마지막으로 다른 사람의 외형을 빌려와서 해당 pose로 원본 이미지를 변형하는 pose transfer 기법이나, 비디오에서 실시간으로 translation을 하는 video-to-video translation 기법(vid2vid)도 존재한다.
물론 CV 분야가 워낙 그 범용성이 넓기 때문에, 여기에 열거하지 않은 다양한 분야가 존재하며 각 분야에서 계속해서 활발한 연구가 진행중이다.
Reference
Mask R-CNN
Mask R-CNN(2)
GAN을 이용한 Image to Image Translation: Pix2Pix, CycleGAN, DiscoGAN