개요
오늘은 object detection을 위해 제시된 다양한 모델들과 또한 CNN의 동작 중 모델이 내포하고 있는 기댓값, 혹은 모델이 출력과정에서 만들어내는 feature map 등에서 의미를 찾기 위한 방법론인 CNN visualization 기법에 대해 배웠다.
이 글은 아래와 같은 내용으로 구성된다.
Object Detection
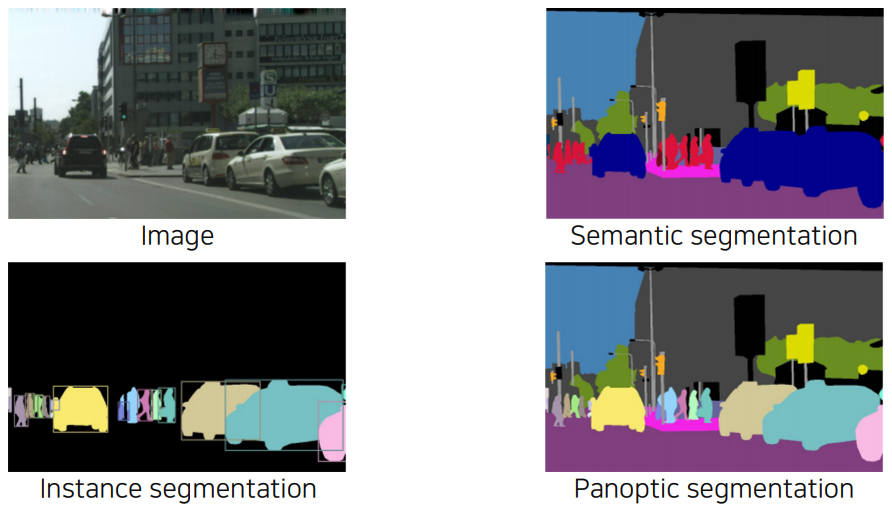
저번 포스트에서는 semantic segmentation에 대해 다루었다. 여기서는 주어진 물체 전부에 대한 어떤 구분선을 긋는 것이 주요 목적이다.
더 진보된 형태로는 instance segmentation, panoptic segmentation 등이 있는데 여기서는 category 뿐만 아니라 instance도 구분해낸다.
panoptic segmentation은 instance segmentation에서 좀 더 진보된 형태이다.
오늘 다룰 object detection은 경계선과 각 물체의 위치정보를 정확히 인식함은 물론, 그 물체가 무엇인지까지 분류해내는 작업을 말한다. 보통 사진은 2차원 형태이므로 bounding box는 왼쪽 위 꼭짓점과 오른쪽 아래 꼭짓점의 x, y좌표, 그리고 해당 물체의 class까지 총 5가지의 정보를 저장하고 있게 된다. (혹은 좌측 상단의 x, y좌표와 높이, 너비 값으로 표현되기도 한다. 둘 모두 위치정보 4개가 필요하다.)
object detection은 regional proposal과 classification 단계가 분리되어있는 two-stage detection과 별도의 regional proposal 추출 단계 없이 한번에 detection이 이루어는 one-stage detection으로 나눌 수 있다.
Two-stage detector
two-stage detector의 앞단에서 regional proposal을 제시해줄 수 있는 알고리즘에 대해 알아보자.

고전적인 알고리즘의 대표적인 예로 HOG 방법이 있다.
이미지의 local gradient를 해당 영상의 특징으로 활용하는 방법이다.
간단하게만 보면, 이 알고리즘에서는 픽셀별로 x축, y축 방향 gradient(edge)를 계산하고 각 픽셀별 orientation을 histogram으로 표현한다. 그리고 인접한 픽셀들끼리 묶어 블록 단위 특징 벡터를 구한다. (CNN의 kernel로 찍는 방법과 유사) 이렇게 하면 의미있는 특징을 가진 regional proposal응ㄹ 구할 수 있게 된다.
HOG 알고리즘을 제시한 논문에서는 보행자 검출을 수행하였는데 보행 중인 사람과 가만히 있는 사람 두 가지 클래스를 SVM을 통해 분류하였다.

한편, regional proposal을 위한 또다른 알고리즘으로 Selective search(SS)가 있다.
여기서는 먼저 비슷한 특징값(i.e., 질감, 색, 강도 등)을 가진 픽셀들을 sub-segmentation한다. 그래서 초기에는 아주 많은 영역을 생성해낸다.
그 다음 greedy algorithm으로 작은 영역을 큰 영역으로 통합해나간다. 여기서도 역시 비슷한 특징값을 가진 것들이 우선순위이다.
이렇게 후보군이 1개가 될 때까지 반복한다.
SS 알고리즘을 제시한 논문에서도 최종적인 object recognition(object detection) 분류를 위해 SVM을 활용하였다.
그럼 이제 regional proposal을 만드는 방법을 알아보았으니 classfication 방법론들에 대해 알아보자. 여기서는 근본적으로는 딥러닝, 즉 CNN을 활용한 기법들에 대해 알아볼 것이다.
아래 제시하는 초기 two-stage 방법론들은 regional proposal 단계에서 selective search를 활용하였다. 다만 two-stage detector도 후속 모델들은 위에서 제시한 알고리즘 없이 regional proposal을 스스로 찾아낸다.
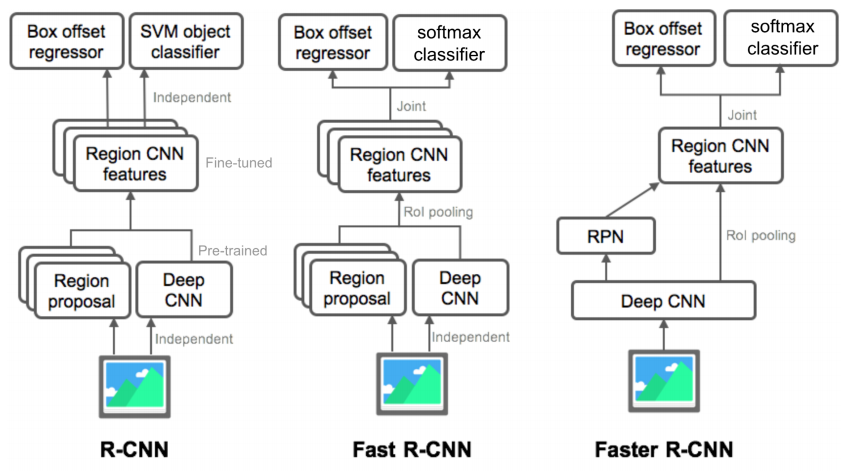
R-CNN
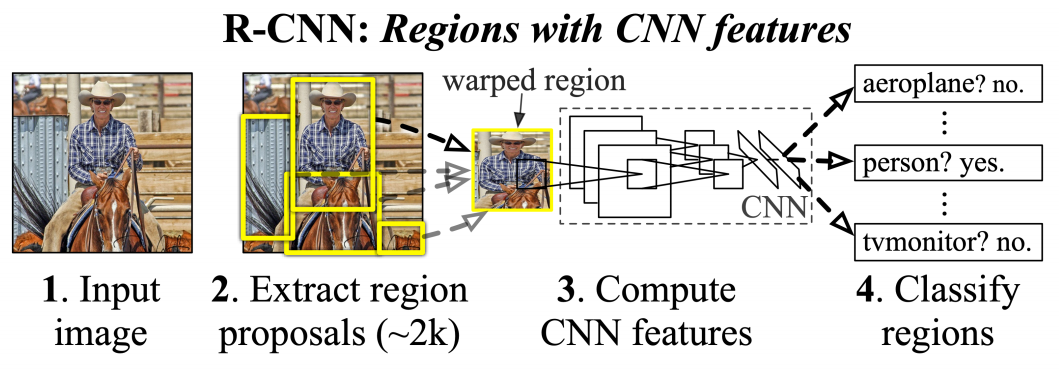
R-CNN 모델에서는 먼저 regional proposal을 뽑아낸다. 박스 후보군은 다른 말로 RoI(Region of Interest)라고 한다.
다음으로, 추출한 RoI들을 CNN에 통과시키기 위해 모두 동일 input size로 만들어(warp)준다. 물론 CNN의 input은 가변적일 수 있지만 여기서는 최종 classification을 위해 FC layer를 활용하였기 때문에 고정된 input size가 필요하다.
마지막으로 warped RoI image를 각각 CNN 모델에 넣고 출력으로 나오는 feature vector로 SVM classification을 통해 결과를 얻는다. 여기서는 먼저 이 bounding box가 객체가 맞는지 판별하고 객체가 맞다면 어떤 객체인지까지 판별하는 역할을 수행한다.
추가적으로 SS algorithm으로 만들어진 bounding box가 정확하지 않기 때문에 물체를 정확히 감싸도록 만들어주는 bounding box regression(선형회귀 모델)도 마지막에 활용한다.
이 방법론이 제시될 당시에는 데이터가 비교적 적었는지 softmax를 통한 분류보다 SVM이 더 좋은 성능을 보였기 때문에 SVM이 사용되었다. 그런데 현재와 같이 데이터가 많을 때 R-CNN 방법론을 다시 활용한다고 하면 softmax와 SVM 중 어떤 방법이 더 좋은 정확도를 보일지도 궁금해지는 대목이다.
이 방법은 RoI 수가 2000개가 넘기 때문에 CNN을 너무 많이 돌려야하고 무엇보다 CNN, SVM, boundinx box regression 각각의 pipeline이 다르기 때문에 이를 end-to-end로 학습시키는 것이 불가능하다는 단점이 있다.
그래서 이 두 문제를 해결한 Fast R-CNN이 등장하게 된다.
Fast R-CNN
Fast R-CNN은 RoI pooling 기법을 활용하여 이 두 문제를 해결하였다.
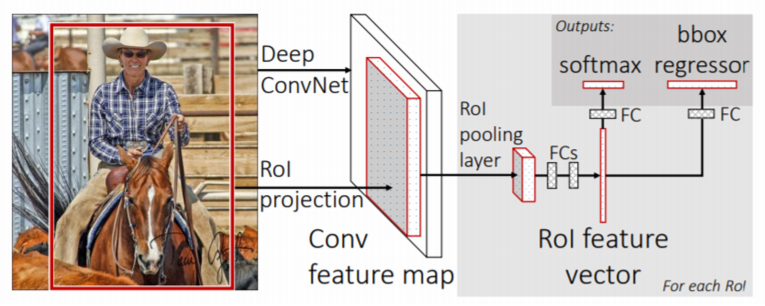
여기서도 먼저 SS를 통해 RoI를 찾는다. 그 다음 전체 이미지를 먼저 CNN에 통과시켜 전체에 대한 feature map을 얻는다.
그리고 이전에 찾았던 RoI를 feature map 크기에 맞추어 projection 시킨 후 여기에 RoI Pooling을 적용하여 각 RoI에 대한 고정된 크기의 feature vector를 얻는다.
마지막으로 이 feature vector 각각을 FC layer에 통과시킨 후 이번에는 softmax로 분류를 하고 앞서 언급한 bounding box regression도 함께 적용하여 최종적인 bounding box 및 class 분류 출력을 내놓는다.
방금 중간에 각 RoI에 대한 고정된 크기의 feature vector를 얻어내는 과정이 있었다. 즉, 여기서는 input size에 대한 제약을 타파하여 warp 과정이 없어진다.
좀 더 자세히 보면, 이 부분에서는 max pooling이 되는데 정확히는 고정된 크기의 출력이 나오게끔 max pooling이 된다.
이 부분은 사실 우리가 원래 알던 CNN의 max pooling과 조금 다르다.
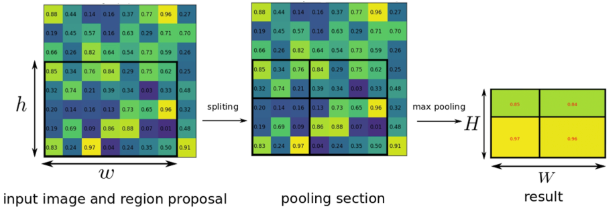
맨 왼쪽 그림이 feature map이고 검은 바운딩이 RoI일 때 고정된 크기의 출력 $H \times W$가 나오게끔 max pooling을 해야한다.
만약 RoI의 크기가 $h \times w$이면 여기서는 $H \times W$의 feature를 얻기 위해 RoI를 $\frac{h}{H} \times \frac{w}{W}$ 크기만큼 grid를 만들어 각 그리드에서 max-pooling을 수행하게 된다.
결국 의도된 크기로 풀링이 되었기 때문에 고정된 크기의 feature vector를 얻을 수 있게 된다.
여담으로 이 RoI pooling은 SPPNet이라는 피라미드 구조의 모델에서 처음 활용한 기법을 모티브로 한것인데, Fast R-CNN에서는 피라미드 구조는 활용하지 않았지만 고정된 크기로의 max-pooling을 했다는 공통점이 있다.
아무튼 다시 Fast R-CNN으로 돌아와보자. 요약하면 CNN 연산이 1번밖에 사용되지 않아 연산량 측면에서 이점을 확실히 가져갔으며 CNN을 먼저 적용하고 warp 없이 RoI를 projection시키고 연산한 것이라서 classification 단계에서 end-to-end 학습이 가능하다.
다만 아직 regional proposal을 별도의 알고리즘을 통해 수행하기 때문에 완벽한 end-to-end 학습이 불가능하다는 단점이 있다. 또한 Fast R-CNN은 사실 RoI 추출 단계가 대부분의 실행시간을 차지한다는 점이 critical하므로 이 부분에 대한 개선이 필요하다. 따라서 이를 해결한 Faster R-CNN 모델이 제안된다.
Faster R-CNN
Faster R-CNN은 RoI 추출을 위해 RPN(Region Proposal Network) 단을 도입한다. 참고로, 그 뒷단은 Fast R-CNN과 완전히 동일하다. 물론 학습이 end-to-end로 이루어지기 때문에 region proposal을 찾는 단과 classification을 수행하는 단이 동시에 학습된다는 차이점도 있다.
아무튼 그래서 여기서는 RPN에 대해 알아보도록 한다.
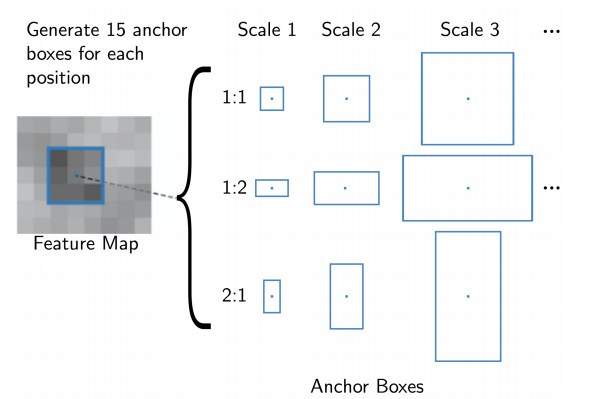
여기서는 anchor box라는 개념이 있는데 그냥 미리 rough하게 정해놓은 후보군의 크기 정도로 이해하면 된다.
hyperparameter이며, 원 논문에서는 박스의 scale과 비율을 각각 3종류씩 주어 총 9개의 anchor box를 활용하였다.
Faster R-CNN에서는 미리 학습 데이터를 정하게되는데, 모든 픽셀에 대하여 anchor box를 다 구해놓고 ground truth와의 IoU score를 계산하여 0.7보다 크면 positive sample, 0.3보다 작으면 negative sample로 활용하게 된다.
IoU(Intersection over Union) score는 주어진 두 영역의 (교집합 영역)/(합집합 영역)이다. 즉, 영역의 overlap이 많으면 이 score가 높게 나오게된다.
참고로 IoU score가 0.3에서 0.7 사이인 샘플은 학습에 도움이 되지 않는다고 판단하여 원 논문에서는 이를 학습에 활용하지 않는다.
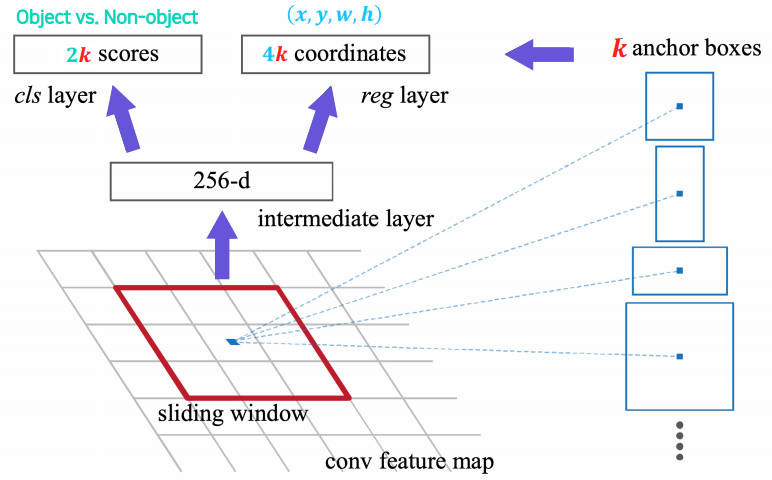
RPN의 input은 CNN을 먼저 통과한 feature map이다.
input에 3 x 3 conv를 하여 256d로 channel을 늘린 후 cls layer와 reg layer에서는 각각 1 x 1 conv를 통해 2k, 4k channel을 가지는 feature를 얻게된다. (k는 anchor box의 수이다)
cls layer의 output 2k개에서는 해당 위치의 k개의 anchor가 각각 개체가 맞는지 아닌지에 대한 예측값을 담고, reg layer의 output 4k개에서는 box regression 예측 좌표값을 담는다.
개인적으로 이 부분이 잘 이해가 되지 않는다. k개의 channel에 대하여 각각 anchor size를 지정해주지 않았는데 어떻게 단순히 2k/4k의 conv 연산으로 각각이 우리가 원하는 conv에 대한 예측값이 되는지 의문이다. 지금 당장 이해하기로는, loss를 통한 학습을 하기 때문에 k개 각각이 의도하는 anchor box size에 대한 예측값이 되도록 학습이 될 것 같다.
또한 논문에서 제시하는 바로는 그냥 cls layer에서 logistic regression을 적용하기 위해 output k channel로 conv를 수행해도 된다고 한다. 이 부분도 궁금했던 대목이었다.
아무튼 여기까지 하고 나면 대충 물체(object)가 맞는지에 대한 확률값을 알 수 있게 되는데, 이제 이를 내림차순으로 정렬한 후 높은 순으로 K개의 anchor만 추려낸다. 그 다음 K개의 anchor에 대한 bbox regression을 해준다. 그러면 이제 개체일 확률이 높은 anchor에 대한 위치 값까지 알게 되는데 여기서 Non-Maximum Suppresion(NMS)를 적용한다.
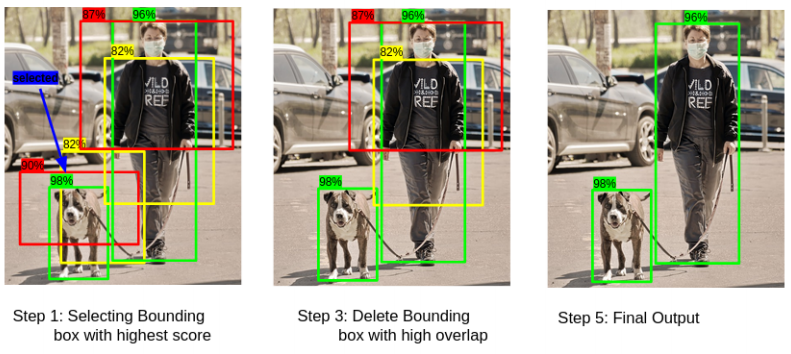
NMS는 후보군 anchor box에서 허수/중복 데이터를 필터링하는 역할을 한다. 여기서는 IoU가 0.7이상인 anchor box에서 확률 값이 낮은 박스를 지워낸다.
논문에서는 NMS를 적용해도 성능 하락이 얼마 없었지만 효과적으로 proposal의 수를 줄일 수 있었다고 언급하고 있다.
이렇게까지 하면 최종적인 anchor 후보군을 선정할 수 있게 된다. 남은 것은 앞서 본 Fast R-CNN을 위에서 만들어낸 proposal에 적용하는 것 뿐이다.
R-CNN family의 구조를 전체적으로 summary해보자면 아래와 같다.
Single-stage detector(One-stage detection)
single stage detector는 정확도는 조금 떨어질 수 있지만 그 속도가 매우 빠를 것으로 예상해볼 수 있다. two-stage detector에서는 region proposal에 대한 RoI pooling 단계가 필요했지만 여기서는 그런 단계 없이 곧바로 box regression과 classification을 수행하게 된다. 다만 최근 연구에는 two stage detection임에도 속도가 빠르다고 기술되어있는 thunderNet 등의 architecture도 있다. 따라서 속도든 정확도든 어느 것이 우월하다라는 것을 이분법적으로 가리기는 어려울 듯하다.
one-stage detector의 대표적인 주자로 YOLO(You only look once)가 있다. YOLO는 특히 real time object detection에서 뛰어난 성능을 보여 많은 파장을 불러일으켰다.
YOLO
YOLO는 Reference 페이지에 그림으로 된 설명이 너무 잘 나와있으니 해당 자료를 참고하는 것이 더 좋을 듯하다. 일단 그래도 정리는 해본다. ![]()
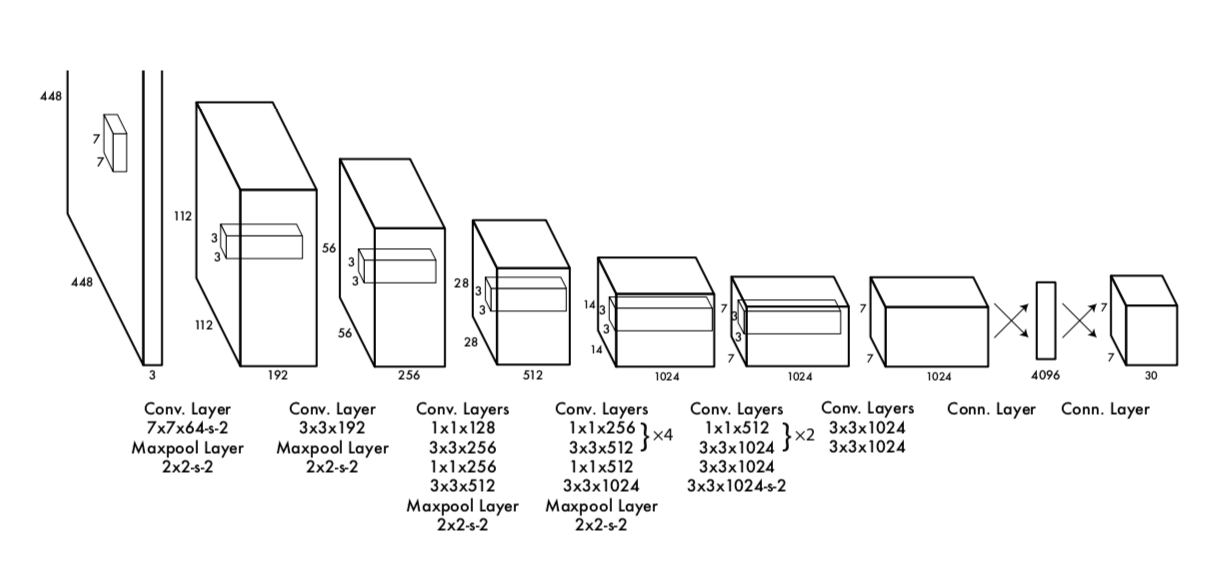
YOLO는 위와 같이 어찌보면 평범한 CNN architecture에서 돌아가게 된다. 개인적으로 네트워크 자체에는 별다른 변형이 없는데도 혁신적인 task를 할 수 있었다는 점이 좀 놀라웠다.
다만 loss 설계가 기존 classfication과는 좀 다르다는 점에 주의하자. 애초에 최종 output이 tensor 형태로 나오기 때문에 loss 설계가 다른 것이 당연하기는 하다.
아무튼 위 네트워크를 거쳐 나온 최종 output는 7 x 7 x 30의 tensor이다. 30개 채널 중 앞 10개는 바운딩 박스의 (x, y, w, h)라는 위치 정보와 obj score라는 신뢰도 지수를 담는다. 원 논문에서는 바운딩 박스의 개수(hyperparameter) B=2로 설정하였기 때문에 이러한 정보가 2개 있어 총 10개가 된다. 뒤 20개는 각 class일 확률 값이다. 역시 원 논문에서는 20개 클래스 dataset을 활용하였기 때문에 이 부분이 20이다.
앞에서 obj score라는 신뢰도 지수를 언급했는데, 이것은 $P(\text{Object}) \times \mathrm{IOU} ^{\text{truth}} _{\text{pred}}$로 계산된다. 그런데 실제 학습 단계에서는 현재 보고 있는 그리드에 물체가 존재하면 $P(\text{Object})=1$, 없으면 $P(\text{Object})=0$으로 설정되므로 결국 이 값은 물체가 존재할 때 IoU 수치가 되며 존재하지 않으면 0이 된다.
뒤 20개에 해당하는 각 클래스별 확률은 $P(\text{Class}_i \, \vert \, \text{Object})$이라고 볼 수 있다. 따라서 obj score와 클래스별 확률을 곱하면 $P(\text{Class}_i) \times \mathrm{IOU}$, 즉 해당 박스가 특정 클래스일 확률 값을 나타낼 수 있게 된다. 여기에 IoU가 곱해짐으로써 해당 박스가 그 클래스에 얼마나 부합하는지까지 고려할 수 있게 된다.
여기서는 B=2(바운딩 박스 후보 수)이므로 7 x 7 각 그리드에서 바운딩 박스 2개씩에 대한 class별 확률을 앞서 말한 방법으로 구할 수 있다. 여기에 앞서 본 NMS algorithm을 적용하면 최종적인 output을 얻을 수 있게 된다.
YOLO의 loss function은 아래와 같다.
앞에 $\mathbb{1}_{ij}^{\text{obj}}$ 이런식으로 붙어있는 것은 NMS까지 거친 최종 prediction에 대해서만 살펴보겠다는 의미이다. 이것은 전체 box에 대해 보지 않고 최종 예측으로 나온 값들에 대해서만 loss를 계산하겠다는 의미라고 이해하면 된다.
(1), (2), (3)은 ground truth와의 x, y, w, h, C(confidence) 차를 계산해주는 부분이다. 다만 w, h 쪽은 루트를 씌웠기 때문에 그 가중치를 덜해줬다고 이해하면 될 것 같다. $\lambda_{\mathrm{coord}}$는 물체가 있을 때의 오차와 없을 때의 오차 간의 비율을 맞춰주기 위한 것인데 논문에서는 모두 5로 설정하였다. 그래서 이 부분은 물체가 있다고 판단한 부분들의 위치 조정(혹은 신뢰도 조정) 정도로 이해하면 될 것 같다.
(4)는 못 찾아낸 물체에 대한 패널티를 매기는 부분이다. 못 찾아낸 물체(ground truth)와의 IoU가 가장 높은 인덱스를 $\mathbb{1}_{ij}^{\text{noobj}}$으로 나타내었다.
마지막으로 (5)는 물체가 있다고 판단한 인덱스 $i$에 대하여 모든 클래스에 대한 예측 값과 실제 값의 차이를 loss에 반영하는 부분이다.
SSD
SSD(Single Shot MultiBox Detector)는 앞서 YOLO의 문제점을 좀 더 해결하고 속도 및 정확도를 끌어올린 모델이다. YOLO는 마지막에 7 x 7 grid로 나누고 거기서 bounding box를 확장하기 때문에 그리드 크기보다 작은 물체는 탐지하지 못한다는 문제점이 있었다. 또한 마지막 output만을 활용하기 때문에 보다 detail한 정보를 고려하지 못한다는 단점도 있었다.

SSD에서는 위와 같이 pre-train model을 거친 이후 나오는 모든 Conv 과정에서 feature map들에 object detection을 수행하고 여기서 나온 각각의 결과를 최종 detector/classifier에 통과시켜 detection을 수행한다.
여기서는 bounding box의 수(B) 뿐만 아니라 Faster R-CNN에서의 anchor box처럼 피처맵 크기별 default box를 설정해놓고 해당 박스에 bounding box regression 및 confidence level을 계산한다. 이 부분이 YOLO와의 주요한 차이점 중 하나라고 할 수 있다.
그래서 bounding box regression에 해당하는 4 * B channel의 텐서, classification에 대한 정보에 해당하는 (class수 20 + 배경 클래스 1) * B channel의 텐서를 각 레이어에서 가져와 object detection을 수행한다.
RetinaNet
사진을 보면 소수의 positive example(개체)가 있고 그 외 대부분의 공간들은 negative sample(배경)인 경우가 많다. 하지만 앞서 본 one-stage detector들은 classifier로 cross entropy loss를 활용하기 때문에 과도하게 많은 negative sample 때문에 학습이 잘 진행되지 않을 수 있다.
따라서 이러한 class imbalance한 상황을 막기 위해 RetinaNet 논문에서는 Focal loss라는 새로운 손실함수를 제안한다.
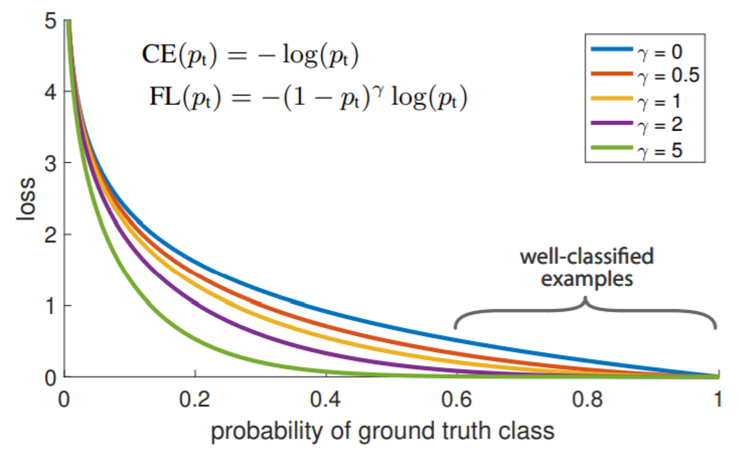
여기서는 맞히기 쉬운 샘플(easy example)에 대한 gradient는 적게 흘려주고, 맞히기 어려운 샘플(hard example) 혹은 잘못 판별한 샘플(misclassified sample)의 gradient를 크게 흘려주어 학습을 촉진한다. 위와 같이 loss를 설계하면 $\gamma$값이 커짐에 따라 이러한 gradient 조정 효과가 더 강해지는 것을 확인할 수 있다.
특히 Focal loss가 주요하게 해결한 문제는 easy negative sample에 대한 문제이다. 앞서 말했듯이 이미지에는 negative sample이 훨씬 많은 편이다. CE loss를 활용하면 gradient가 적게 흘러도 그 수가 너무 많아 이것이 학습을 방해하게 된다. 극단적인 예시로는 0.1의 gradient를 1000번 흘려주는게 10의 gradient를 10번 흘려주는 것보다 더 값이 크다는 것을 들 수 있다. Focal loss를 활용하면 이러한 문제를 최소화할 수 있게 된다.
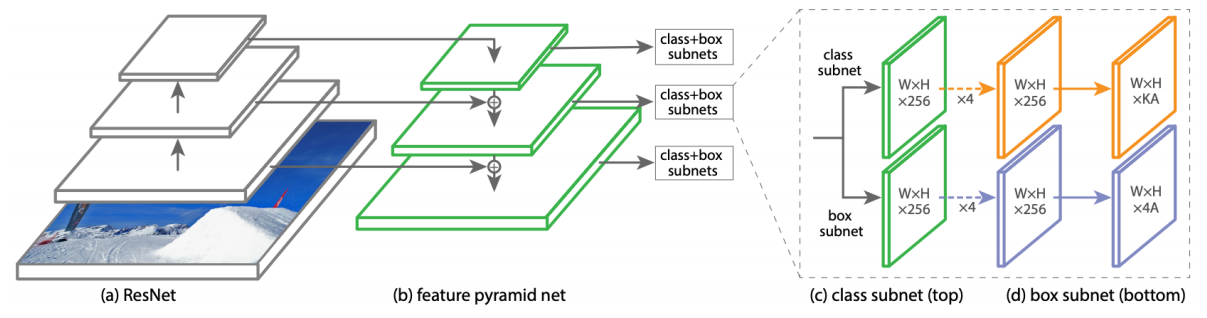
RetinaNet은 또한 FPN(Feature Pyramid Networks) 구조를 사용한다.
U-Net과 거의 유사한 구조인데 U-Net과 달리 concatenation 대신 이전 layer의 output과 sum을 한다.
마지막으로 이렇게 나온 output을 두 방향에 흘려주어 classification과 box regression을 각 위치마다 dense하게 수행하게 된다. 여기에는 FCN(Fully convolutional network)가 활용되었다.
RetinaNet은 기존 YOLO의 성능을 뛰어넘고 더불어 2-stage detector의 성능까지 앞지르는 성과를 보여주게 된다. loss를 약간 변형함으로써 놀라울 정도의 성능 향상을 이루어냈다는 점에 주목할 만하다.
Detection with Transformer
NLP에서 혁신을 불러온 transformer 구조가 다른 task에서도 활용될 수 있다는 점은 앞선 포스트에서도 많이 언급하였다. Object detection에서도 transformer 구조를 활용한 다양한 시도가 있었다.
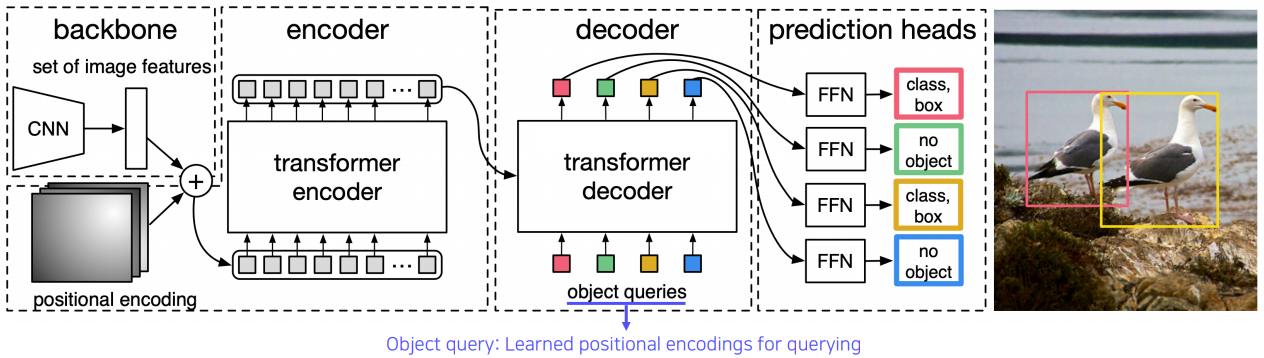
DETR(DEtection TRansformer)도 그 중 하나이다.
여기서는 먼저 이미지를 인코딩하고 object query를 통해 transformer에게 질의를 한다.
object query는 위치에 대한 정보(학습된 positional encoding)라고 이해하면 된다.
그러면 모델이 해당 위치에 어떤 물체가 있는지, 박스는 어떻게 그려야하는지에 대한 정보를 출력해준다. 이 부분에 대해서는 자세히 설명하지는 않지만, 유수의 대기업들에서 이러한 transformer 기반 vision 연구가 진행되고 있다는 점이 주목할 만하다. DETR 역시 Facebook에서 제시한 모델이다.
Other
앞선 모델들에서는 계속해서 bounding box를 regression 해왔는데, 요즘은 더이상 bounding box regression 외에 다른 형태의 박스 탐지가 가능한지에 대한 연구도 진행되고 있다.
물체의 중심점을 대신 찾는다던지, 박스의 왼쪽 위 점 과 오른쪽 아래 점만 찾는 것으로 계산을 단순화한다든지 등의 방법이 있으며 이는 추후에 더 자세히 다루어보도록 한다.
CNN Visualization
신경망 모델을 설계하고 성능을 평가하고나면 왜 성능이 이렇게 나오는지, 어떻게 하면 모델의 성능을 개선할 수 있을지 쉽게 감이 잡히지 않는다. 왜냐하면 신경망 모델은 대부분 깊게 쌓여있고 그 가중치를 하나하나 쳐다보면서 의미있는 결과를 도출해내는 것은 현실적으로 어렵기 때문이다.
그래서 우리는 이 신경망 내부에서 어떤 일이 벌어지고 있는지 살펴보기 위해 visualization 기법을 활용해볼 수 있다. 여기서는 그 중에서도 CNN의 Visualization 방법에 대해 알아보도록 한다.
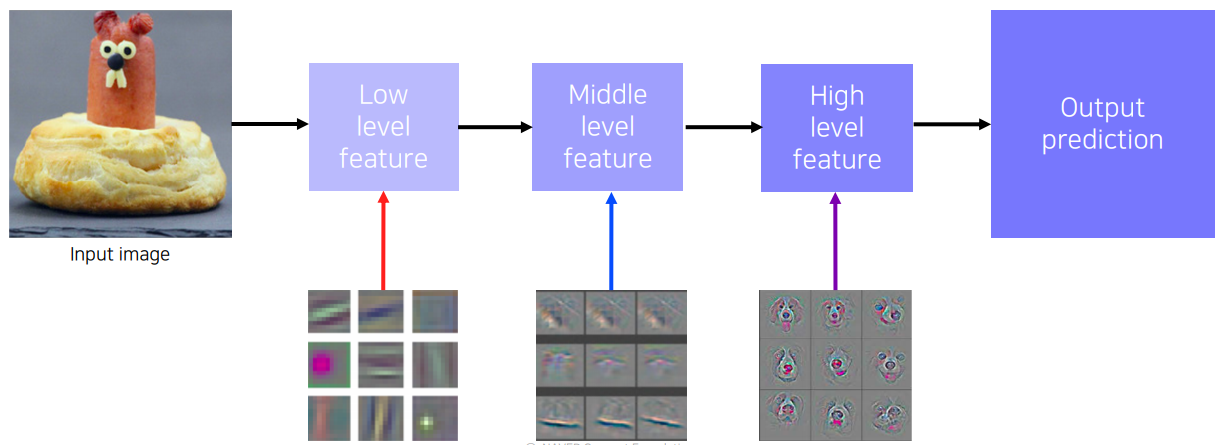
CNN은 위와 같이 level별 feature가 담고있는 정보가 다르다. (물론 다른 신경망들도 레이어 깊이별 나타나는 정보가 다르다)
따라서 CNN에서는 각 레벨별로 어떤 feature를 분석해볼 수 있는지 고려해보아야 한다.
신경망을 시각화한다고 하면 크게 model behavior(행동) 분석을 위한 시각화와 model decision(결과) 분석을 위한 시각화로 나뉜다.
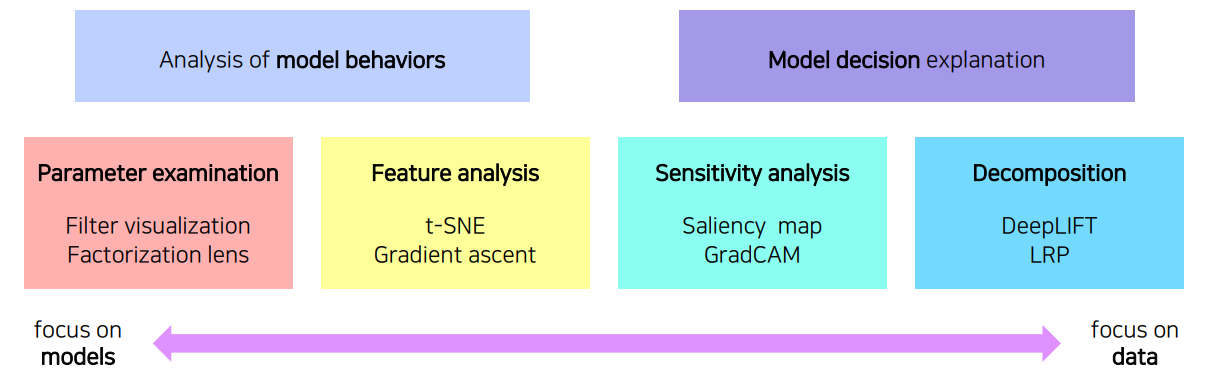
각각에서의 대표적인 방법론은 위와 같다.
Analysis of model behaviors
먼저 high level feature(분류 직전)를 살펴보도록 하자. 가장 간단하게는 여러 이미지의 마지막 feature들의 Nearest Neighbors를 생각해볼 수 있다. feature들간의 거리를 측정하고 거리가 이웃한 이미지들이 사람이 직접 봐도 비슷한 모습을 보이는지 속하는지 살펴보겠다는 뜻이다.
feature들간의 거리는 그냥 계산해도 되지만, 고차원 벡터는 시각화하기 어렵다는 단점이 있다. 그래서 feature들을 이해하기 쉬운 2차원 공간에 나타내기 위한 시도가 존재하였다.
feature의 차원축소를 위한 많은 기법이 있지만, 그 중에서도 t-SNE(t-distributed stochastic neighbor embedding)가 좋은 임베딩을 보이는 것으로 알려져있다. 이를 통해 우리는 2차원 평면에서 여러 피처들의 거리를 직접 보면서 모델이 보는 이미지간 유사도와 사람이 보는 이미지간 유사도의 차이를 생각해볼 수 있다.

위 그림은 t-SNE를 이용한 MNIST dataset의 시각화 모습이다. 사람이 보기에도 비슷하게 생긴 숫자 3과 8이 모델이 내놓은 feature space에서도 비슷한 거리에 위치하고있음을 확인할 수 있다.
다음으로, mid level과 high level 사이에서 나오는 feature맵을 가지고 layer activation을 생각해볼 수 있다.
여기서는 보고있는 레이어의 출력(hidden node)에서 각 채널이 이미지의 어느 부분에서 활성화가 되는지 살펴본다.

그 결과 위와 같이 hidden node에서 channel들 각각이 어느 부분을 중점적으로 보는지 확인할 수 있다.
이를 통해 CNN은 중간중간 hidden layer들이 물체를 여러 부분으로 나누어 보고 이들을 조합하여 물체를 인식하는 것이라고 추측할 수 있다.
또다른 방법으로 maximally activating patches, 즉 활성화된 것들 중에서도 최대 크기로 활성화된 뉴런의 주변을 시각화해볼 수 있다. 이 방법은 (1) focus할 특정 레이어와 채널을 정하고 (2) 여러 이미지를 통과시킨 후 (3) activation이 최대인 부분의 receptive field를 crop해온다.

위 그림은 hidden node별 activation이 큰 값을 가진 patch를 가져온 모습이다.
각 hidden node별로 활성화가 잘되는 형태가 다른 것을 알 수 있다.
어찌보면 각각의 hidden node가 자신이 담당하는 특정 모양을 찾는 detector 역할을 하고 있다고 볼 수 있다.
마지막 방법으로, 데이터를 넣어주지 않고 모델 자체가 내재하고있는(기억하고있는) 이미지를 분석하는 class visualization 방법이 있다. 여기서는 원하는 class의 이미지가 나오도록 입력값을 최적화해준다. 이것은 사실상 인공의 이미지를 generate하는 과정이다.
결국 우리가 원하는 것은 이미지 $I$이고 이를 모델이 원하는 클래스 $C$로 분류하기를 원하므로 위 식에 따라 $I$를 최적화해주면 우리가 원하는 이미지를 얻을 수 있다. 뒤에는 L2 Regularization이 들어가는데, 이는 이미지에 극단적인 값이 들어가는 것을 방지하기 위해 넣어준다.
maximize하는 과정이므로 gradient ascent가 쓰인다. 다만, 부호를 반대로 해주면 당연히 gradient descent과정이 될 것이고 우리가 전에 역전파로 하던 것처럼 최적화를 해주면 된다.
좀 더 방법을 자세히 살펴보면, 처음에는 그냥 blank/random image를 첫 input으로 넣고 output을 도출해낸다. 이후 모델은 학습하지 않고, input에 gradient를 전달하여 이미지를 수정해나간다. 물론 목표 함수를 최대화하는 것이 목표이며 원하는 target class의 score가 높게 나오도록 input에 역전파를 반복적으로 전달하면서 원하는 이미지를 만들어낸다. 이 generate 과정을 살펴보면 당연히 초깃값 설정이 중요하다는 것을 알 수 있다.
Model decision explanation
여기서는 모델이 원하는 출력을 내기까지 입력을 어떠한 각도로 보고 있는지 알아보기 위해 이를 시각화해본다.
먼저 saliency test(특징 추출) 계열의 방법 중 하나인 occlusion experiments부터 알아본다.

여기서는 간단하게 input 이미지의 일부를 마스킹한채로 모델에 통과시켜 원하는 클래스에 대한 확률 값을 구한다.
그리고 이 확률값을 가린 부분의 heat라고 생각하고 전체 부분에 대한 heatmap(occlusion map)을 그린다.
그럼 최종적으로 이 heat가 강한 부분(salient part)이 model의 decision에 큰 영향을 준다고 생각해볼 수 있다.
다음으로 backpropagation을 통해 saliency map을 그려볼 수도 있다. (via backpropagation)
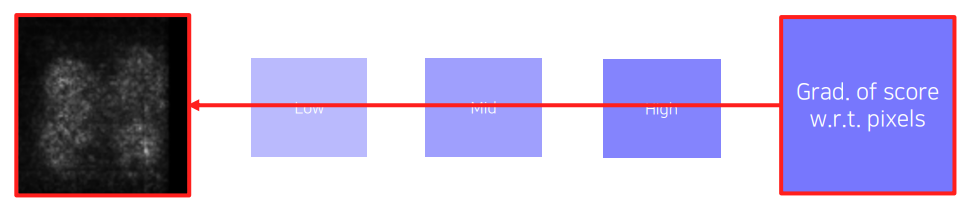
이 방법의 기본 가정은 역전파가 큰 scale로 전달되는 부분이 decision에 큰 영향을 준다라는 것이다.
여기서는 (1) target source image를 모델에 넣어 원하는 클래스의 score를 찾고 (2) 역전파를 input단까지 전달하여 (3) input까지 전달된 gradient magnitude의 map을 그린다. magnitude map을 그릴 때 부호는 중요하지 않으므로 gradient에 절댓값을 취하거나 제곱을 취하여 이를 map으로 그리면 된다.
이 방법은 class visualization과 하는 작업은 비슷하지만 input이 다르고 목적하는 바가 다르다는 점에서 조금의 차이가 있다.
backpropagation을 통해 saliency map을 구하는 방법에는 이것보다 advanced한 방법이 있다. 바로 guided backpropagation이라는 방법인데, 여기에 앞서 deconvolution 연산에 대해 먼저 짚고 넘어가자.
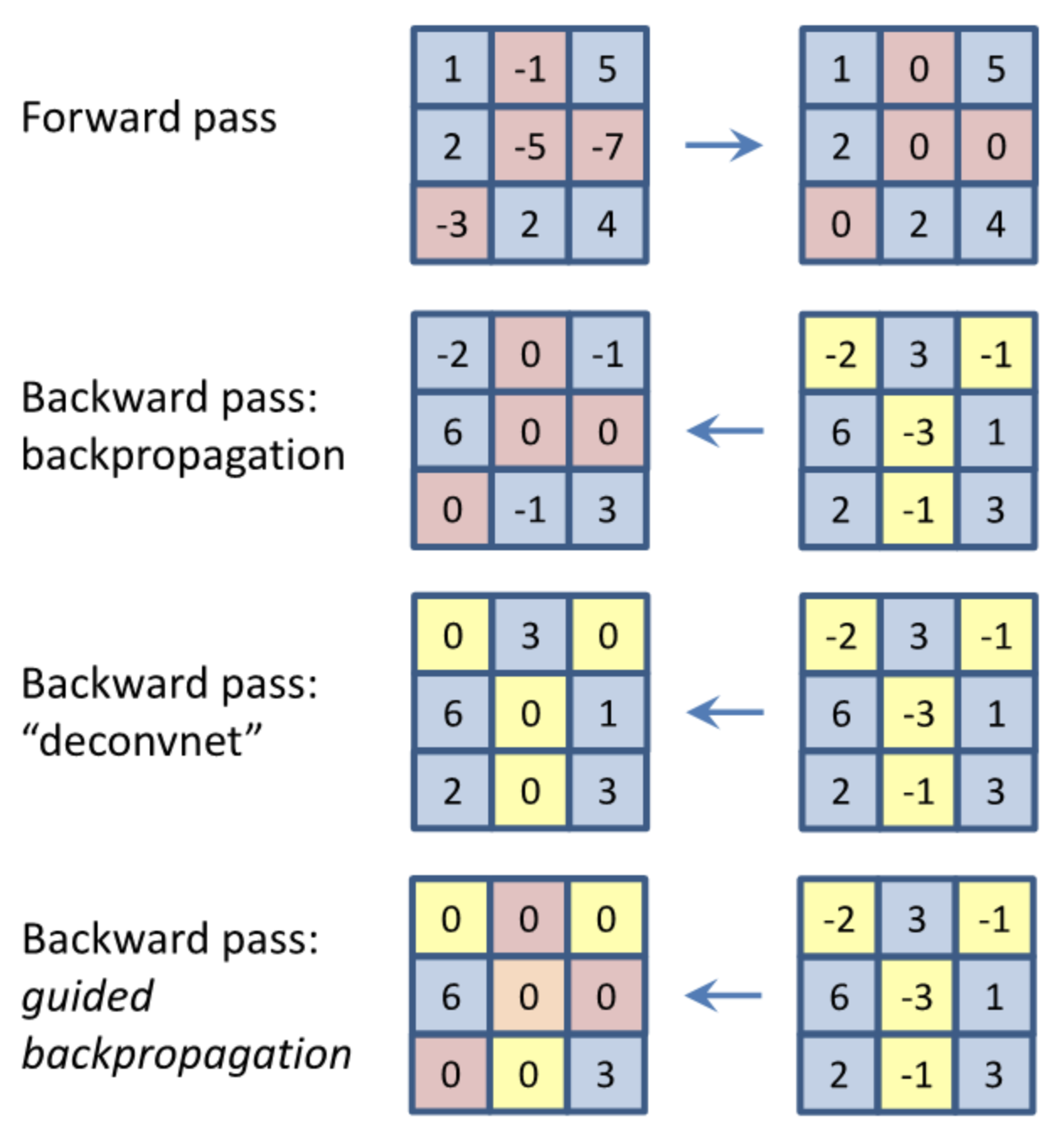
일반적인 conv net의 backward pass에서는 forward 단의 ReLU가 활성화된 부분에서만 gradient가 흐르게 된다.
그런데 deconvnet에서는 forward pass와 무관하게 backward pass의 부호만 고려(즉, backward에 ReLU 적용)한다.
그리고 guided backpropagation에서는 backward pass에서 forward 단의 ReLU와 backward 단의 ReLU 둘 모두를 고려한 gradient가 흐른다.
정리하면, $h^{l+1} = max(0,h^l)$일 때, 아래와 같다.
이게 왜 두 마스크를 둘다 활용하는게 좋은지, 그 이유에 대해서는 수학적으로 증명이 안된 듯하다. 조금은 휴리스틱한 방법론으로 보인다.

위와 같이 guided backprop에서 이미지의 critical한 feature가 좀 더 clear하게 드러나게 되는 것을 실험적으로 알 수 있다.
Model decision explanation - CAM/Grad-CAM
마지막으로 visualization 방법으로 널리 통용되는 CAM(Class activation mapping) 방법에 대해 알아보도록 한다.

이 방법을 통해 위와 같이 decision에 큰 영향을 주는 부분에 대한 heatmap을 얻을 수 있다. threshold를 잘 조정하면 semantic segmentation에도 활용할 수 있을 것으로 보인다.
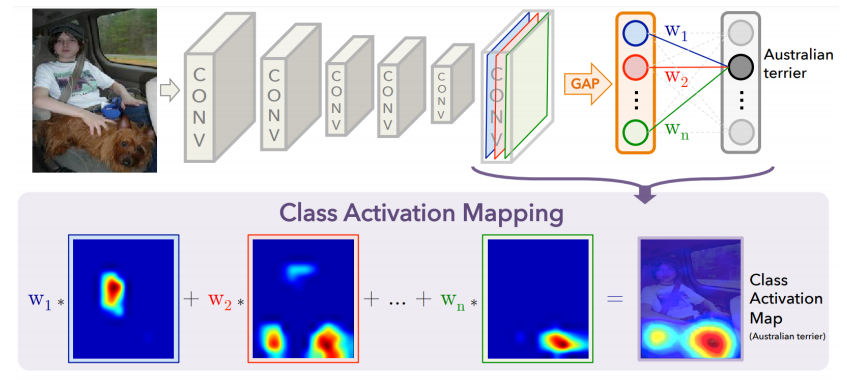
이 방법을 쓰려면 반드시 모델의 마지막 decision part에서 GAP(global average pooling)과 FC layer가 순차적으로 활용되어야 한다.
heatmap을 찍기 위해 이 GAP의 결과 $F_k$와 FC layer의 weight $\mathrm{w} _k$가 활용되기 때문이다.
일단 위 조건을 만족하는 모델의 pre-training이 완료되었으면, 이제 target image를 모델에 넣고 (1) GAP의 결과인 $F_k$들과 (2) 그 값들이 원하는 클래스의 값으로 연결되는 FC layer의 weight 값 $\mathrm{w} ^c _k$들을 가져와서 클래스 $c$에 대한 score 값 $S_c$를 구한다. score 값을 구하는 구체적인 식은 아래와 같다.
(6)은 scoring 식을 나타낸 것이고, (7)은 GAP 연산을 풀어서 쓴 것이다. (8)은 식의 순서를 변경한 것이다. 우리가 필요한 것은 GAP 연산을 하기 전, 공간 정보까지 남아있는 class activation이다. 따라서 최종적으로 우리가 활용할 부분은 공간정보를 합치기 이전 $\sum\limits_{k} \mathrm{w} _{k}^{c}f_k(x,y)$ 항이다. 이 부분을 CAM이라고 부르며, 우리가 원하던 그 값이다.
그래서 이렇게 하면 위에서 봤던 그림처럼 각 feature map 별로 가중합이 연산되어 최종적으로 class activation map을 얻을 수 있게 된다.
이 방법의 장점은 따로 위치 정보에 대한 annotation 없이도 사진의 주요한 부분의 위치정보를 쉽게 찾을 수 있다는 것이다. 하지만, 앞서 말했듯이 대상 모델이 GAP 구조를 활용해야하기 때문에 target 모델에 GAP이 없다면 GAP을 삽입하고 새로 재학습시켜야한다는 단점이 있다. 게다가 이 과정에서 기존 모델과 decision 성능이 다르게 나올 수도 있다는 문제도 있다.
마지막으로 이러한 CAM의 단점을 해결한 Grad-CAM을 살펴보도록 하자.

Grad-CAM은 모델의 구조 변경이나 이에 따른 재학습 과정이 필요하지 않다.
직관적으로 이해해보면, 결국 우리한테 필요한 것은 $\sum\limits_{k} \mathrm{w}_{k}^{c}f_k(x,y)$이고 여기서 $f$는 GAP 이전의 feature map이므로 여타 모델에서도 충분히 얻어낼 수 있다.
그럼 결국 필요한 것은 $\mathrm{w}$인데, 이 부분도 사실 기존 모델은 놔두고 이전에 얻은 feature map에 따로 GAP을 취하여 얻을 수 있다.
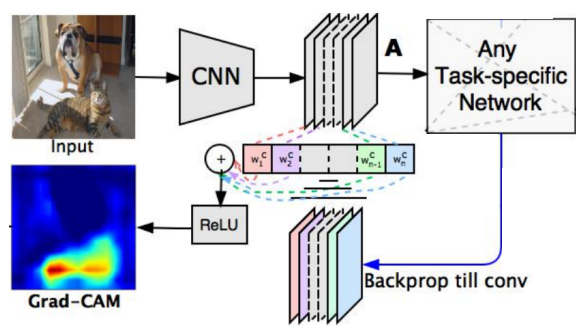
즉, decision task를 위한 layer를 모델에서 제외하고 마지막으로 conv 연산을 통해 나온 feature에 GAP을 취하고 이를 다시 feature와 곱해서 최종적으로 원하는 heatmap을 얻을 수 있다.
결국 가중치 값도 얻을 수 있는데, 중요한 것은 Grad-CAM에서는 그 이름에 걸맞게 그냥 feature map 대신 backpropagation에서 나온 해당 feature의 gradient map을 활용한다는 점이다. 왜 이것을 활용하는지 그 이유에 대해서는 앞서 backpropagation을 통해 얻었던 heatmap이 시각화가 잘되었다는 점에서 찾을 수 있다. 한편, 마지막 feature의 gradient만을 활용하기 때문에 backprop도 그 부분까지만 흘려주면 원하는 값을 얻을 수 있다.
결론적으로 이를 식으로 나타내면 아래와 같다. $\alpha ^c _k$가 standard CAM에서의 $\mathrm{w} ^c _k$와 같은 역할(가중치)을 하고 $A ^k$가 앞에서의 $f ^k$와 같은 역할(feature)을 한다.
결국 이전과 다른 점은 gradient를 활용한다는 점, 그리고 앞서 본 gradient에 ReLU를 적용했을 때의 장점을 취한다는 점 뿐이다. gradient를 활용한다고 해도 원래 CAM과 방법론면에서는 달라진 것이 없다.
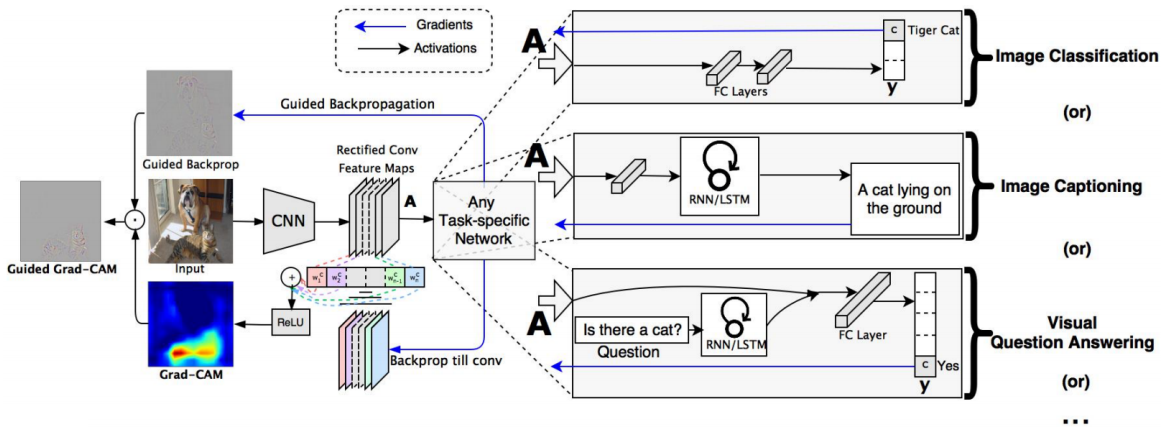
Grad-CAM에서는 위와 같이 Guided Backpropagation 방법도 함께 활용한다.
guided backprop에서는 sensitive, high frequency의 정보를 얻을 수 있고 Grad-CAM에서는 class에 민감한 정보를 얻을 수 있으므로
이들 결과를 모두 활용하면 여러 관점에서의 정보를 모두 고려할 수 있게 된다.
최종적으로는 이 둘 값의 dot 연산을 통해 결과를 도출해낸다.
위에서 오른쪽 그림은 다양한 task에 대해 이를 적용할 수 있다는 것을 나타낸 그림이다.
Other
지금까지 여러 visualization 기법들을 보면서 CNN의 각 layer가 담당하는 역할이 제각기 다르고 이를 사람도 짐작할 수 있다는 점을 알 수 있었다.
이 점을 좀 더 응용하면, 생성모델(GAN 등)에서 사진의 특정 부분을 인식하는 역할을 하는 hidden layer에 찾아가 원하는 부분에 masking을 하여 생성 모델이 우리가 원하는 것을 생성하도록 유도할 수도 있다. 이 예시처럼 사람이 hidden layer의 각 channel의 의미에 대해 잘 파악할 수 있다면 여러 task에 이를 응용할 수 있을 것이다.
PyTorch - Autograd
앞서 본 CNN Visualization에서는 forward pass 중간의 feature map을 뜯어오거나, backward pass 중간의 gradient를 뜯어오는 작업이 필요하다.
그런데 우리는 nn.Module로 모듈 클래스를 짜고 모든 레이어를 안에 넣는다. 그럼 중간에서 feature/gradient를 채오려면 모델을 분리해야하는걸까?
정답은 당연히 ‘그럴 필요가 없다’이다. PyTorch에서는 hook function을 제공한다. 이 함수를 통해 우리는 원하는 layer에 hook을 걸어놓고 forward/backward pass에서 해당 레이어를 통과할 때 그 값을 낚아채서 이용할 수 있다.
먼저 이것에 대해 알아보기 전에 PyTorch의 Autograd에 대해 먼저 알아보도록 하자.
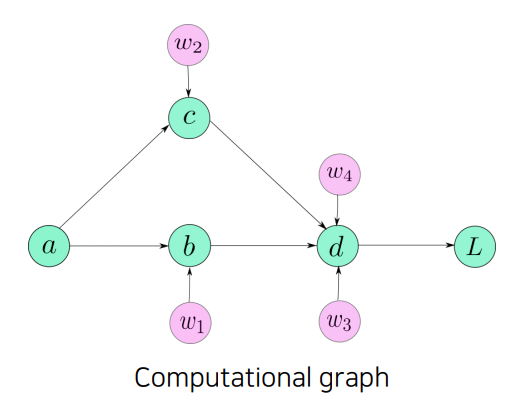
Autograd는 gradient를 계산하기 위해 PyTorch에서 제공하는 API이다. 물론 이렇게 미분을 자동화해주는 API는 여느 DL Library에 모두 존재한다.
대부분이 그렇지만, 여기서도 연산에 관여하는 각 가중치들에 대하여 위와 같이 computational graph를 생성하여 이를 forward pass/backward pass에 활용한다.
autograd는 torch tensor에 대하여 requires_grad 옵션만 True로 되어있다면 어디에서든 활용할 수 있다.
즉, 꼭 Variable() 클래스의 weight 값이 아니어도 된다는 뜻이다.
import torch
x = torch.randn(2, requires_grad=True)
y = x * 3
gradients = torch.tensor([100, 0.1], dtype=torch.float)
y.backward(gradients)
print(x.grad) # tensor([300.0000, 0.3000])
위 코드를 보면 단순한 계산그래프에서도 backward pass가 가능하고, grad를 출력할 수 있다. 300과 0.3이 나온 이유는 backward의 input이 100, 0.1이기 때문이다. 이로부터 마지막 layer의 gradient(즉, backward pass의 첫 번째 단계)의 input은 반드시 1이며, 그 이후부터는 이전 layer에서 계산된 gradient가 다음 layer의 input으로 들어갈 것임을 알 수 있다.
x의 requires_grad 옵션을 True로 주지 않으면 에러가 나게 된다. 이 경우 계산 그래프를 저장하지 않기 때문에 backward pass를 돌 수 없기 때문이다.
또 하나 주의할 점은, 보통 backward pass를 한 번 돌면 자동으로 이전 계산 그래프의 gradient를 지워버린다는 점이다.
...
gradients = torch.tensor([100, 0.1], dtype=torch.float)
y.backward(gradients)
print(x.grad) # tensor([300.0000, 0.3000])
y.backward(gradients)
print(x.grad) # RuntimeError!
이는 웬만해서는 backward를 다시 돌 일이 거의 없을 뿐더러 지금과 같이 변수가 얼마 없으면 상관 없지만 큰 모델에서 계산 그래프 저장 자체가 메모리를 엄청나게 잡아먹기 때문에 이루어지는 조치이다.
다만, 필요할 경우 backward를 돌기 전에 retain_graph 옵션을 True로 주면 계산 그래프를 저장하여 재활용할 수 있다.
...
gradients = torch.tensor([100, 0.1], dtype=torch.float)
y.backward(gradients, retain_graph=True)
print(x.grad) # tensor([300.0000, 0.3000])
y.backward(gradients)
print(x.grad) # tensor([600.0000, 0.6000])
이 경우, 위와 같이 gradient가 축적되는 것을 확인할 수 있다.
이제 앞에서 말했던 hook에 대해 살펴보도록 하자.
방법은 매우 간단하다. 그냥 모델에서 낚아채고 싶은 레이어의 register_hook 메소드를 활용하면 된다.
...
class AlexNet(nn.Moudule):
def __init(self):
...
self.conv1 = nn.Conv2d(...)
def forward(self, input):
x = input
...
x = self.conv1(x)
...
return x
def hook_func(module, input, output):
print('input: ', input)
print('output: ', output)
net = AlexNet()
net.conv1.register_forward_hook(hook_func)
위 코드에서 보이듯이 사용법이 매우 직관적이다. 앞서 말했듯이 원하는 레이어에서 register 메소드로 미리 정의해둔 function을 걸면 된다.
register_hook 관련 method는 torch.nn의 내장 메소드이다.
관련 메소드를 잠깐 훑자면, register_forward_hook()는 forward pass 통과 전/후에 접근할 수 있으며 argument로 module, input, output이 들어간다. register_forward_pre_hook()는 forward pass 통과 전에 접근할 수 있으며 argument로 module, input이 들어간다. register_backward_hook()는 backward pass 통과 전/후에 접근할 수 있으며 argument로 module, grad_input, grad_output이 들어간다. 만약 클래스 내부의 메소드로 hook function이 들어갈 경우 argument의 module을 self로 대신하면 된다.
앞서 계속 argument에 대해 언급했는데 register_hook 메소드들은 반드시 prototype을 지켜야하기 때문이다.
prototype을 지키지 않으면 에러가 발생한다. 만약 원하는 argument가 더 있으면 hook function에 argument를 넣고 functools.partial을 이용하면 된다.
관련 설명은 중요하지 않으므로 생략한다.
만약 hook을 다 사용했으면 다시 해당 layer에 remove() 메소드를 적용하면 register된 모든 hook을 지울 수 있다.
hook 사용이 메모리에 많은 영향을 주는 경우 이렇게 등록한 hook을 지워주는 작업도 필요할 수 있을 것이다.
그럼 이렇게 hook 사용이 메모리에 영향을 주는 경우는 언제일까? CNN Visualization과 같이 feature map을 직접적으로 저장해야하는 경우일 것이다. 물론 이것도 아래와 같이 쉽게 구현할 수 있다.
...
save_feat = []
def hook_feat(module, input, output):
save_feat.append(output)
return output
...
hook function만 잘 다룬다면 visualization을 위한 feature map들을 가져오는 일종의 전처리 과정을 쉽게 해낼 수 있다.
Reference
R-CNN
Faster R-CNN
YOLO
YOLO(2)
RetinaNet
CNN Visualization
Class Visualization