개요
오늘은 다양한 감각 정보를 이용한 학습 방식인 Multi-modal learning에 대해 알아보도록 한다.
이 글은 아래와 같은 내용으로 구성된다.
Multi-modal learning
multimodal learning은 서로 다른 양식(감각)의 정보들을 모두 활용하여 원하는 작업을 수행하는 것을 말한다. 사람은 오감을 이용하여 물체의 여러 정보들을 인식하게 되고, 이를 기반으로 무언가 판단을 내릴 수 있다. 마찬가지로 기계도 오감의 정보를 모두 인식 및 활용하게 되면 더욱 고차원의 작업을 수행할 수 있게 되거나, 기존 작업에 대한 고성능의 수행 능력을 기대해볼 수 있다.
여기서는 CV에 대해 다루고 있으므로 Image & Audio, Image & Text를 결합한 작업들에 대해 다루어보도록 한다.
구체적인 기법에 대해 다루기에 앞서, 서로 다른 정보들이 함께 쓰이기 어려운 이유부터 짚고 넘어가보자.
첫 번째로, 가장 큰 이유는 당연히 각 정보에 대한 표현법이 다르기 때문이다. 이미지는 픽셀별로 RGB 값이 들어있는 3차원 이상 텐서에 의해 정보가 표현되는 반면, Text 데이터는 각종 단어 하나하나들이 고차원의 임베딩 벡터로 저장되어 있을 것이다. 그렇다면 음성 데이터는 어떠한가? 이전에 다루어보지는 않았지만 이 또한 그 고유의 형태로 저장되어있다.
두 번째로 정보의 양 역시 불균형하다. 서로 다른 feature를 다루고 있는데 모델이 받아들일 정보의 양은 당연히 다를 수 밖에 없다. 예를 들어 ‘초록색 의자’ 라고 하면 이를 text로 다르게 표현할 방법은 거의 없지만, 이미지로 표현한다면 초록색 의자를 얼마든지 많이 만들어볼 수 있다.
마지막 이유는 앞 두 가지 이유와 연결되는데, 결국 정보의 표현이 다르고 그 양이 불균형하므로 모델 자체가 학습하기 쉬운 데이터 쪽으로 편향될 수 있다는 점이다. 모델은 다양한 감각 정보가 있을 때 최대한 답을 맞힐 수 있도록 쉽게 답을 유도해낼 수 있는 정보에 biased될 가능성이 있다. 사람도 물체를 인식하는 데에 시각 정보를 가장 많이 활용하지만 가끔은 후각이나 청각 등 다른 감각기관을 사용할 일도 더러 있다. 모델 역시 가끔은 다른 정보가 있어야만 원하는 task를 수행할 수 있는 경우가 있는데, 만약 모델이 한쪽에 편향되어있다면 해당 modality 외에는 모델의 결정(decision)에 큰 영향을 주지 못할 것이다.
이러한 단점에도 불구하고, multimodal learning이라는 발상 자체가 학습에 큰 도움이 될 것이라는 점에는 이견을 찾기 어렵다. 위에 나열한 단점들은 우리가 어떻게든 극복해야할 점일 뿐 결정에 있어 고려할 수 있는 데이터가 많다는 점은 여전히 좋은 소식이기 떄문이다.
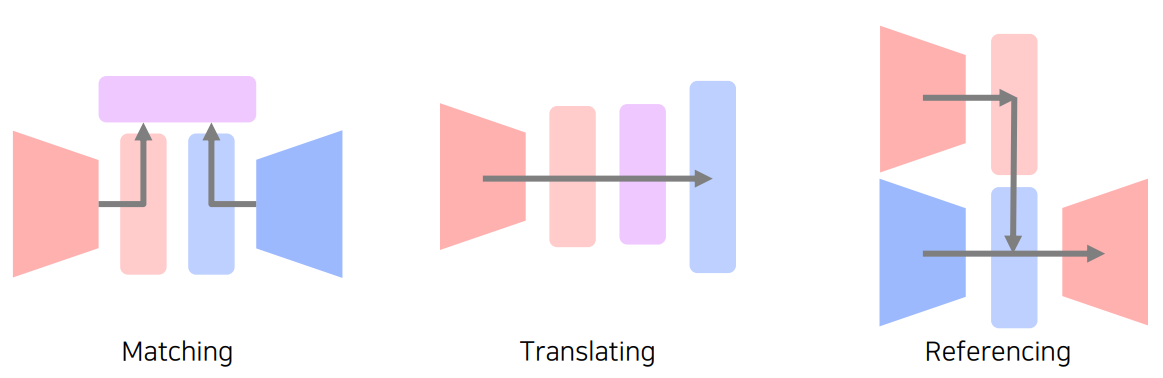
multi-modal learning의 종류는 위와 같이 크게 3가지로 나누어볼 수 있다.
Matching은 서로 다른 두 modality의 정보, 즉 추출된 feature를 같은 dimension의 space로 보내 이를 학습에 활용하는 방식이다.
Translating은 한 modality를 다른 한 쪽의 정보의 형태로 변경하고 이를 활용하는 방식이다.
Referencing은 한 modality가 출력을 낼 때 다른 modality의 정보도 참조하는 방식이다.
지금까지 multi-modal learning의 장단점과 방식들에 대해 알아보았다. 이제부터는 이를 구현한 모델들에 대해 아주 간단히 짚고 넘어갈 것이다.
Multi-modal tasks - Visual data & Text
이미지와 텍스트로 할 수 있는 일이라고 하면 가장 먼저 떠오르는 것은 Image tagging, Image captioning 등이 있다.
Matching
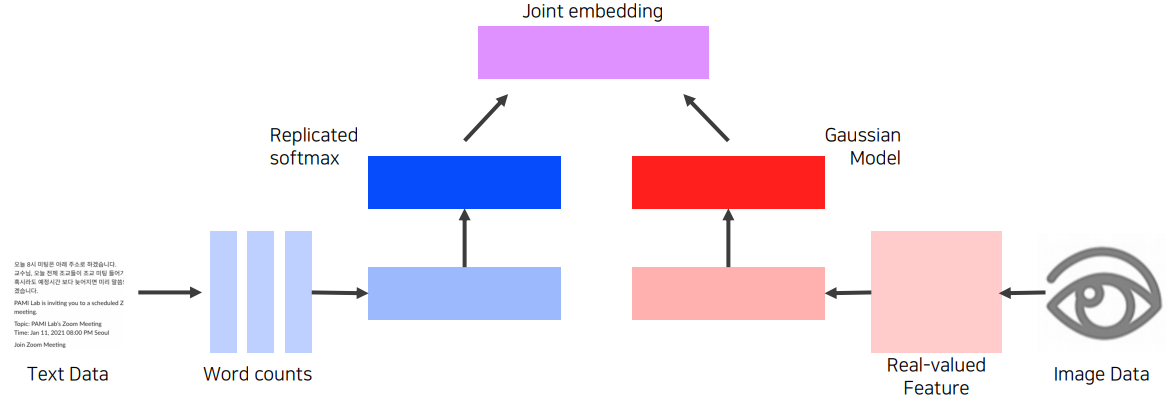
Image tagging은 image로부터 tag를 출력, 혹은 tag로부터 image를 출력(retrieval)하는 task이다.
방식은 앞서 말한 Matching 을 활용한다. 시각 정보와 text 정보를 모두 피쳐벡터화(word embedding, CNN 등)한 이후,
이 둘이 호환되도록 joint embedding을 통해 same dimensional vector로 만들어 similarity(i.e., L2 norm)를 찾아볼 수 있다.
이 경우 예를 들어 ‘개’라는 단어와 개 사진은 비슷한 거리(similarity)를 보여야하며, 반대로 전혀 다른 피처간의 거리는 멀어야 할 것이다. 따라서 위에 기술한 방식대로 학습을 진행하면 최종적으로 image의 피쳐, 혹은 text의 피쳐를 넣었을 때 가장 가까운 거리에 있는 다른 형태의 피쳐를 찾을 수 있다.
물론 이것이 결국 임베딩 벡터를 비교하는 것이라서 두 피쳐간 cosine similarity를 응용하면 NLP에서 봤던 것처럼 image와 text간의 덧셈/뺄셈으로 의미있는 결과를 도출해낼 수도 있다.
이를 RNN과 결합하면 이미지에 대한 문자열 sequence를 얻을 수도 있다. 일례로, 음식의 이미지를 받아 해당 음식의 레시피를 출력하는 Recipe1M+ 모델도 아래와 같이 제시되었다.
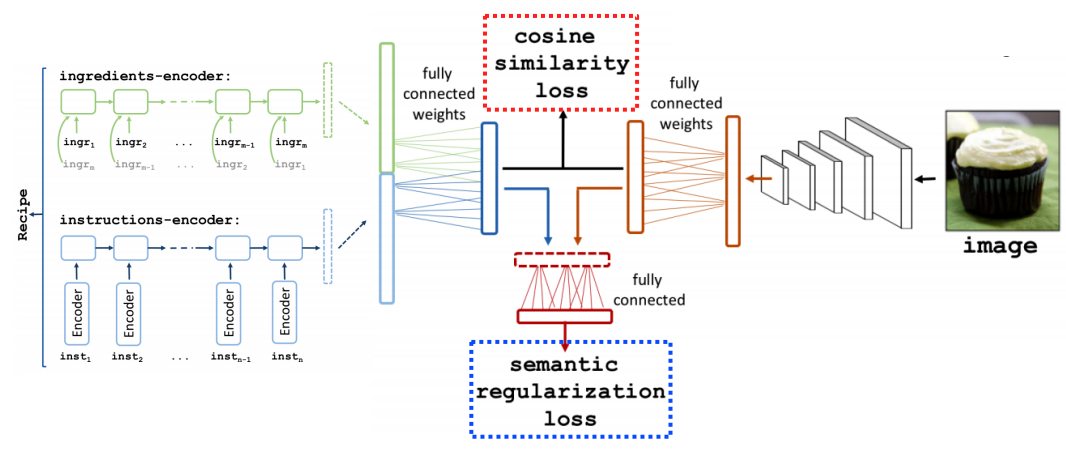
먼저 ingredient sequence와 instruction sequence를 RNN을 통해 뽑아내어 이를 다시 embedding하고 concatenation한다. 한편 다른 쪽에서는 사진에 대한 embedding을 뽑아낸다. 그리고 이 두 벡터간 cosine similarity loss와 semantic regularization loss를 통해 학습을 진행한다.
Translating
Translating*을 활용한 방식으로는 Image captioning이 있다.
image tagging은 image에 존재하는 각 object들의 태그를 출력하는 것이라면,
image tagging은 이미지를 문장으로 설명하는 모델이다.
역시 이 모델도 CNN과 RNN을 결합한 형태의 모델을 활용한다.

image tagging의 대표적인 모델로 show and tell이 있다.
ImageNet으로 pre-train된 CNN에 이미지를 넣고 나온 image encoding vector를 LSTM에 넣어 문장을 얻는 간단한 구조이다.
여기서 더 발전된 모델인 Show, attend and tell은 이미지에서 픽셀별 중요도까지 고려한다. 실제 사진에서는 대부분이 배경이고 중요한 object가 차지하는 비율은 얼마 되지 않는 경우가 많다. Show, attend, and tell 모델에서는 문장을 생성할 때 이미지의 국지적인(local) 부분에 attention을 줄 수 있다.
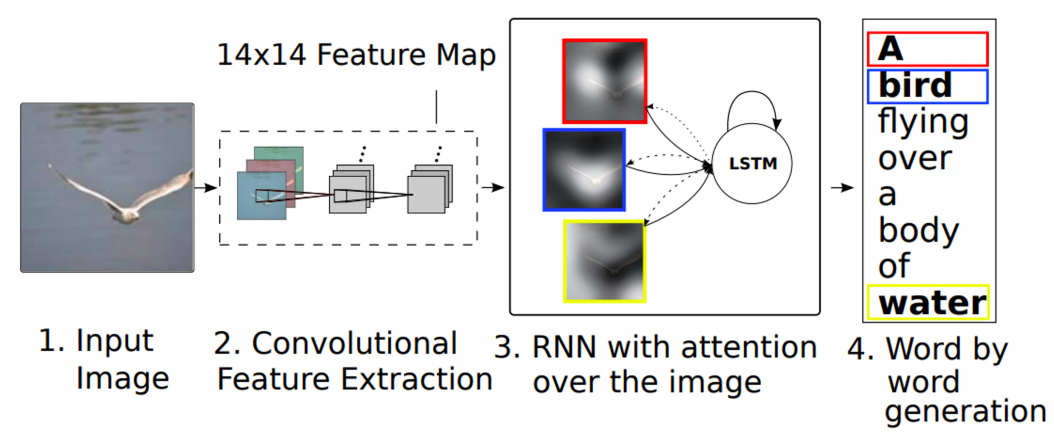
이 모델도 다른 여러 모델처럼 사람의 동작에서 기원했다. 사람도 타인을 볼 때 전체를 계속해서 보기보다는, 눈, 코, 입 등 특징적인 부분만을 중점적으로 바라본다.
이 모델에서는 CNN을 통해 나온 feature을 RNN과 결합하여 어디를 referencing 해야하는지 heatmap을 만든다.
그 다음, heatmap과 CNN에서 추출한 feature를 weighted sum(내적)하여 $\mathrm{z}$ 벡터를 생성한다.
즉, heatmap을 일종의 probability, 혹은 weight으로 보고 attention할 부분을 찾아내는 것이다.
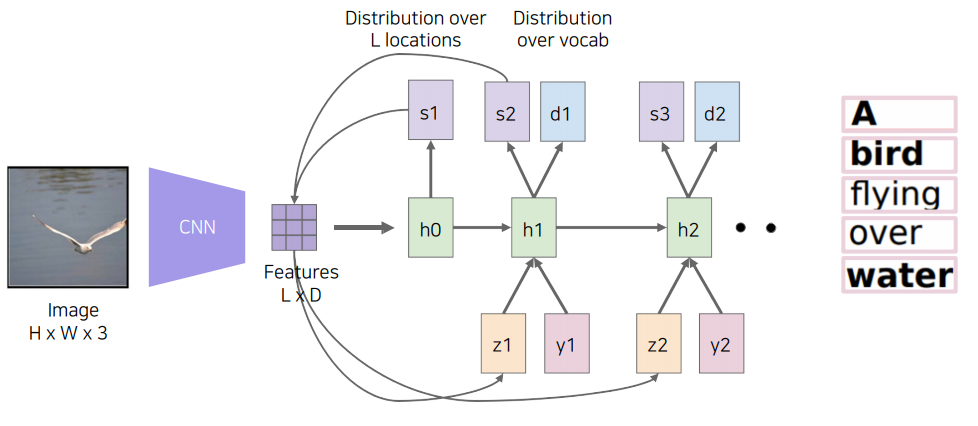
구체적으로 보면 먼저 CNN에서 추출한 feature를 LSTM에 condition($h_0$)으로 넣어준다. 그 다음, LSTM은 이 중에서 어느 부분에 attention을 해야하는지 spatial attention $s_1$을 출력한다.
이제 모델은 이 $s_1$을 가중합(weighted sum)을 위한 weight으로 활용한다.
이전에 구한 feature와 $s_1$을 내적을 취하여 가중합을 구하는 것이다. 그러면 이 때부터 우리가 원하는 단어 $d_1$이 튀어나오게 된다.
위 과정을 RNN 모델을 통해 반복하여 $d_k$가 EOS일 때까지 반복한다.
그렇다면 반대로 문장을 통해 이미지를 생성할 수는 없을까? 이미지에서 문장을 뽑아내는건 N to 1 모델에 가깝지만, 문장에서 이미지를 찾는 것은 1 to N 모델에 가깝다. 즉, 여기서부터는 임의의 무언가를 생성할 수 있는 generative model이 필요하다.
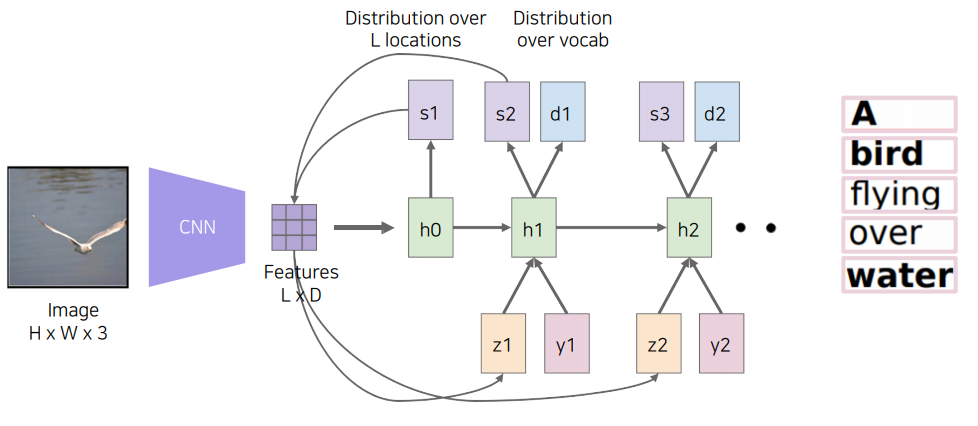
실제로 generative model을 이용한 Text-to-Image 모델을 보면 먼저 text 전체를 fixed dimensional vector로 만든 후 여기에 random code(latent) $\mathrm{z}$를 concat하여
기존 CGAN과 같은 작업을 수행한다. 다만 이전 CGAN과 다른 점은 여기서는 discriminator에 input(문장)이 다시 관여한다는 점이다. 즉, discriminator는 생성된 image와 text에 대한 정보를 모두 가지고 있다.
discriminator는 image와 text의 정보가 concat된 vector가 적절한 문장인지(make sense?) 판별하면서 적대적 학습을 진행한다.
Referencing(reasoning)
referencing 형태의 모델은 어느 task를 수행할 때 다른 감각의 정보도 참고하면서 작동한다. 사실 앞에서 다루었던 show, attend, and tell 모델도 translation보다는 reasoning에 가까운 모델이다. 다만 show and tell 모델과 이어지는 모델이라 앞서서 미리 설명하였다.
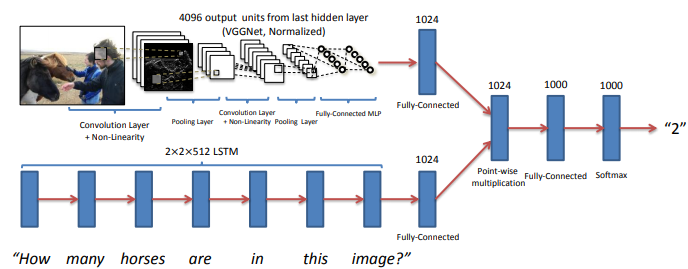
VQA(Visual Question Answering)은 영상과 질문이 주어졌을 때 답을 하는 task이다.
위 모델과 같이 이미지는 CNN 계열로, 질문은 RNN 계열로 각각 fixed dimensional feature을 extract하여 pointwise multiplication한 후 linear layer에 통과시켜 답을 찾는다.
concatenation 대신 pointwise multiplication을 함으로써 두 embedding vector간에 interaction된 vector을 뽑아냈다는 점이 주목할 만하다.
위와 같이 설계된 모델은 end-to-end구조이므로 학습에도 용이하다고 볼 수 있다.
VQA 모델은 전형적인 Reasoning model이다. 서로 다른 두 감각의 정보가 서로 referencing을 하면서 결론을 낸다. 앞서 show, attend, and tell 모델도 언어 정보와 시각 정보가 서로 지속적으로 referencing하면서 답을 이끌어냈다.
Multi-modal tasks - Visual data & Audio
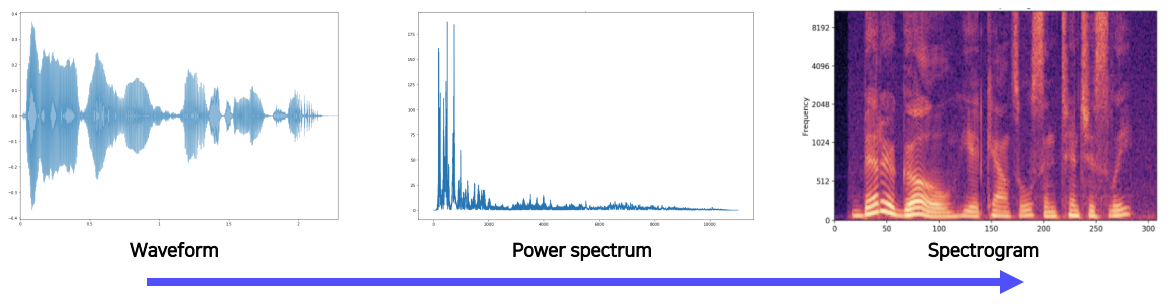
소리 데이터를 다루려면 먼저 acoustic feature인 waveform을 우리가 처리할 수 있는 형태로 변환해야한다.
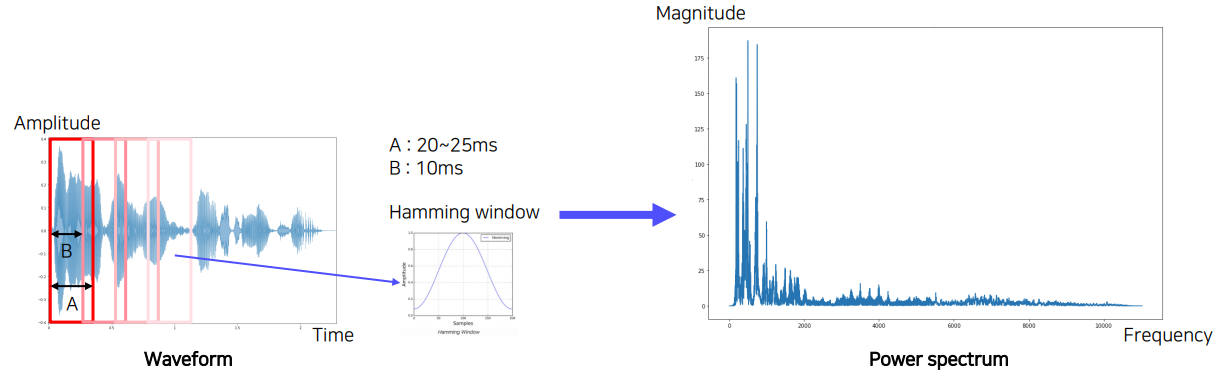
가장 먼저 떠올릴 수 있는 것은 푸리에 변환(Fourier transform)인데, 그렇다고 소리 데이터에 무작정 푸리에 변환을 적용하는 것은 아니다.
중요한 것은 시간 정보가 살아있어야한다. 단순한 푸리에 변환은 시간 정보를 날려버리고 주파수 정보만 남긴다.
이를 위해 Short-time Fourier transform(STFT)를 이용한다. 여기서는 작은 size의 window를 이용한다. 특히 Hamming window라는 것을 이용하는데 이 윈도우는 단순히 wave를 시간구간별로 나눠주는 것뿐만 아니라, 가운데를 강조해주는 역할도 수행한다. 위 사진에 나와있는 것같이 종모양 hamming window를 element wise로 곱하여 가운데가 강조된 waveform을 얻을 수 있다. 당연히 window는 overlap되면서 같은 구간도 여러번 찍히게 된다.
이렇게 찍어낸 짧은 구간의 wave는 푸리에 변환을 통해 주파수가 분해되고 이를 시간별로 나열하면 시간별 주파수 성분이 어떻게 변하는지 알 수 있다. 그리고 이것을 그대로 이미지로 표현하면 이 session의 가장 위에 나와있는 spectrogram의 형태로 나타나게 된다. 요즘은 spectrogram의 차원을 낮춘 형태인 melspectrogram(MFCC를 통해 추출)을 많이 사용하기도 한다.
Matching
여기서도 matching 방식을 사용한다면 joint embedding을 빼놓을 수 없다. 소리와 이미지를 matching하는 task라면 Scene recognition을 떠올릴 수 있다. 즉, 영화의 소리를 통해 이미지 장면을 인식하는 것이다.
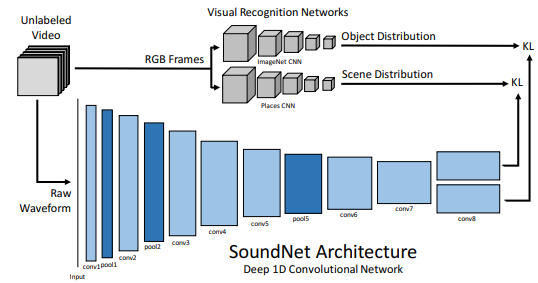
대표적인 model로는 SoundNet이 있다. 이 모델은 2016년에 나온 모델로, 그때는 spectrogram이 상용화되지 않았는지 그냥 raw waveform을 그대로 신경망에 통과시켜 피쳐를 추출하였다.
아무튼 윗단에서는 pre-train된 CNN으로 object와 scene(장소)에 대한 feature를 찾고 아래에서는 raw waveform을 1D CNN에 통과시켜 헤드 2개를 각각을 위한 feature를 2개 뽑아낸다.
각 feature 쌍은 KL Divergence를 통해 분포가 근사된다. 이 때, 학습되는 부분은 audio 1D CNN 단이다. 윗 단은 앞서 말했듯 pre-train된 부분으로 다시 학습을 하지 않는다. 사실상 이미지 정보를 사운드 임베딩에 옮겨주는 작업이라고 이해할 수 있는데, 그래서 이 학습을 sound에 대한 visual knowledge의 transfer, 즉 transfer learning으로도 볼 수 있다.
한편, SoundNet의 audio feature를 추출할 때 중간 단(i.e., pool5)에서 추출된 feature를 따로 뽑아 다른 target task에 응용할 수도 있다. 굳이 중간에서 뽑는 이유는, 뒤에서 뽑으면 너무 task-specific한 피쳐가 뽑힐 것이라는 우려 때문이다.
Translating
translating이라는 이름에 걸맞게, 여기서는 음성을 이미지로 바꾸는 작업을 수행한다. 대표적인 모델은 Speech2Face모델, 즉 목소리로 사람의 얼굴을 추측하는 모델이다.
이 모델은 Module networks 구조로, 각자가 담당하고 있는 역할을 잘 수행할 수 있도록 학습된 여러 module을 결합하여 사용한다.
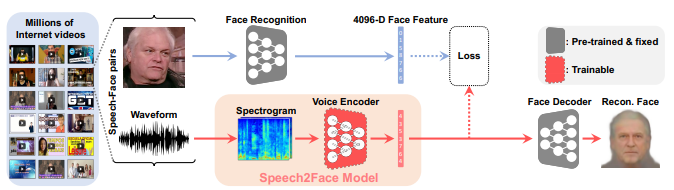
얼굴 이미지를 CNN을 통해 fixed dimensional feature vector로 만들고 audio에 대하여서도 fixed dimensional vector를 만든다.
이 둘 간의 loss를 측정하여 voice를 feature vector로 추출하는 구간을 학습시킨다.
face decoder에서는 audio로부터 추출된 feature벡터를 입력으로 받아 정면 사진을 출력한다.
여기서는 spectrogram을 사용하였다는 특징이 있다. 또한 이 모델은 translation appliation이지만 서로 다른 두 감각의 정보로부터 같은 차원의 벡터 두 개를 추출하고 이를 함께 활용하므로 어떻게 보면 또 joint embedding을 활용하였다고 볼 수 있다.
반대로 Image-to-Speech task도 빼놓을 수 없다. 2020년 12월에 나온 Text-Free Image-to-Speech Synthesis Using Learned Segmental Units이라는 논문에서 제시된 따끈따끈한 방법론이다.
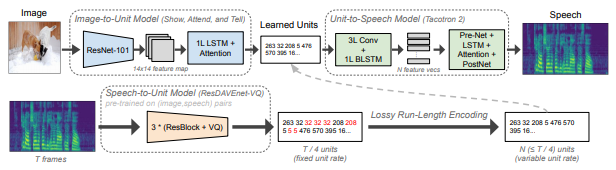
여기서는 먼저 하단 Speech-to-Unit Model을 통해 audio를 어떤 unit으로 추출한다. 그리고 이 unit을 중간에 놓고
image를 통해 이 unit이 나오도록, 그리고 unit을 통해 speech 결과가 나오도록 따로 학습을 진행한다.
더 구체적인 내용은 여기서 다루지 않는다.
Referencing(reasoning)
여기서는 소리의 source가 어디인지를 찾는 task를 수행한다. 소리의 context를 파악 후 모델은 영상(image) 내 어느 object와 이 소리가 매칭되는지를 찾아낸다.
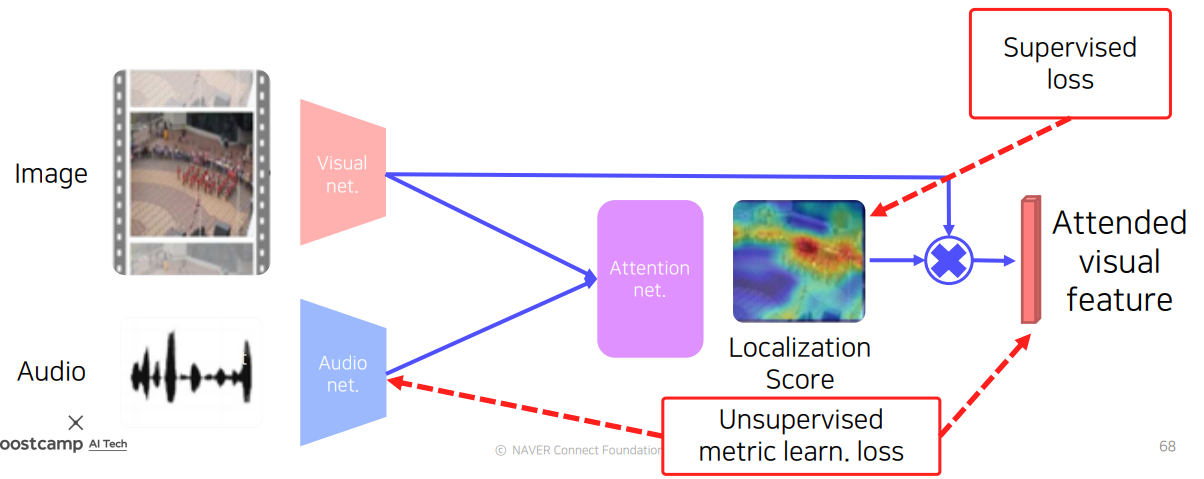
이러한 task를 Sound source localization이라고 하는데, 가장 간단하게는 위와 같이 image, audio에서 각각 feature를 추출하여 둘을 내적하여 localization score가 표시된 heatmap을 찾아볼 수 있다. 이 때, visual feature와 sound feature는 서로 dimension이 달라도 된다. visual은 3차원 텐서맵의 형태 그대로 활용하고 audio는 channel dimension만 살리고 GAP(Global average pooling)하여 둘을 내적하면 된다. 이렇게 하면 사운드에 대한 픽셀별 source score를 찾아낼 수 있다.
위와 같이 heatmap 형태로 나타나있으니 KL Divergence나 L2 norm을 활용하여 supervised learning을 진행하면 된다.
한편, image의 feature map과 localization score(heatmap)을 내적하고 이를 pooling하여 attended visual feature를 뽑아낼 수도 있다. 그리고 이 벡터와 audio feature 간 metric learning(유사하게 만드는 학습)을 진행하여 unsupervised learning 역시 같이 진행할 수 있다. audio 정보는 현 상황에서 중요한 전체 context에 대한 정보를 담고 있고 attended visual feature도 중요한 local 정보를 담고 있으므로 이들간 metric learning은 합당하다.
결국 semi-supervised learning의 형태라고도 볼 수 있는 것이다.
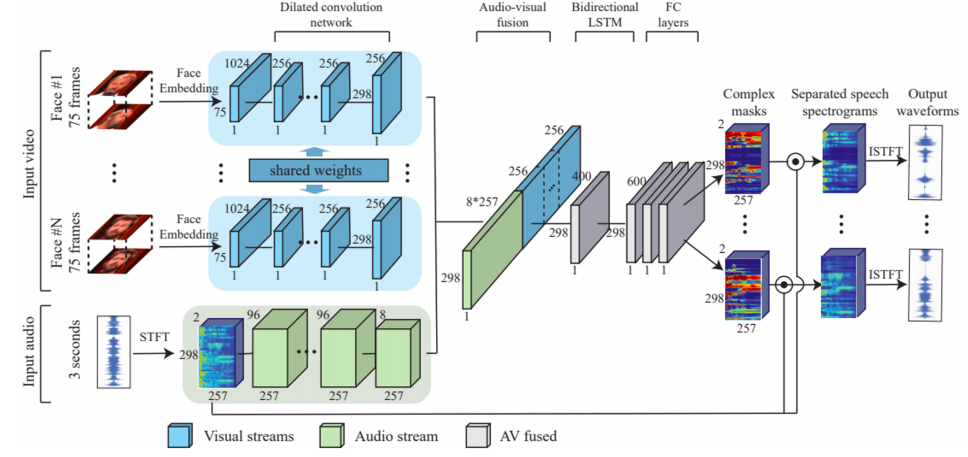
마지막으로 Speech separation은 영상에 나오는 여러 목소리를 사람별로 분리하는 task이다.
먼저 비디오에서 사람별로 feature를 추출하고 audio에서도 spectrogram 및 feature를 순차적으로 추출한다. 그리고 두 feature를 concat하고 이를 통해 각 사람별로 spectrogram을 어떻게 분리해야하는지 complex mask를 추출한다. 최종적으로 spectrogram으로 변환되었던 feature를 끌고와서 complex mask와 element-wise operation을 통해 최종적으로 분리된 N개의 목소리를 추출한다.
참 근사한 방법이지만 문제는 마지막에 있다. 결국 학습을 하려면 분리된 목소리에 대한 label이 필요하다. 즉, 이 학습을 위해서는 이미 분리되어있는 서로 다른 두 사람의 목소리가 필요하다. 여기서는 이 label과 prediction 사이의 L2 loss에 의한 학습을 제안한다.
하지만 목소리를 분리하는게 목표인데 이미 분리된 목소리가 있다는게 말이 안 된다. 그래서 학습을 할 때는 이미 분리된 두 목소리, 즉 서로 다른 두 영상을 끌어와서 인위적으로 합치고 이를 학습 데이터로 활용한다. 즉, synthetically generate된 두 clean speech video를 활용하여 학습을 진행한다.
지금까지 다양한 Multimodal learning 방법에 대해 살펴보았다. 현시점에서 이 multimodal learning의 궁극적 도달지는 자율주행(Autopilot)이다. 실제로 자율 주행은 최근 많은 기업들의 관심사이지만, 아직 완벽히 완성되지는 못한 과제로 남아있다.
자율 주행을 위해서는 시시각각 변하는 단순 시각 정보는 물론이고 운전 중에 발생하는 사운드(경적 소리 등), 텍스트(표지판 등) 등에 대한 정보를 종합적으로 고려하여 decision이 행해져야한다. 다양한 센서 데이터를 활용하는 만큼, 지금 다룬 시각/청각/텍스트 데이터 외에도 많은 정보들이 자율 주행에 이용될 것이다.